

























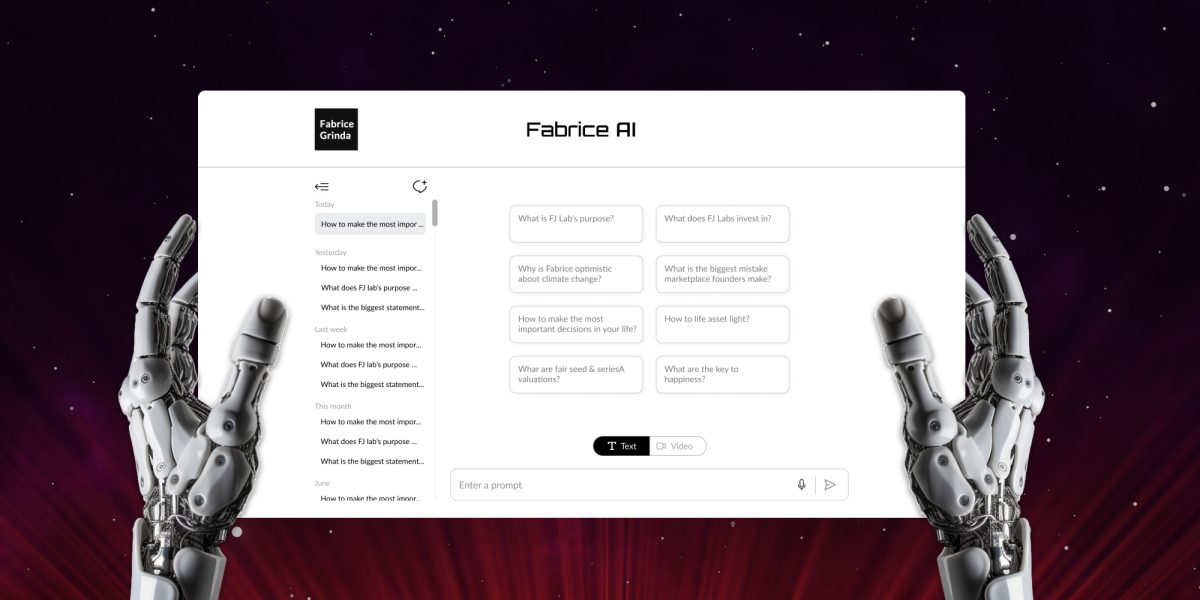
Fabrice AI ist eine digitale Darstellung meiner Gedanken, die auf dem gesamten Inhalt meines Blogs basiert. Sie soll ein interaktiver, intelligenter Assistent sein, der in der Lage ist, komplexe Anfragen nuanciert und präzise zu verstehen und zu beantworten.
Fabrice AI begann als Experiment, ein persönliches Bestreben, das Potenzial der künstlichen Intelligenz zu erforschen, indem ich eine digitale Version des umfangreichen Wissens schuf, das ich im Laufe der Jahre weitergegeben hatte. Ursprünglich stellte ich mir dies als ein einfaches Projekt vor, das in wenigen Stunden abgeschlossen werden konnte. Der Plan war einfach: Ich lud meine Inhalte in die API von OpenAI hoch und erlaubte der KI, damit zu interagieren. Auf diese Weise entstand ein zugänglicher, intelligenter Assistent, der auf der Grundlage der Fülle an Informationen, die ich geteilt hatte, nuancierte Antworten geben konnte.
Als ich mich jedoch auf diese Reise begab, wurde schnell klar, dass die Aufgabe weitaus komplexer war, als ich erwartet hatte. Das Projekt, von dem ich dachte, dass es ein kurzer Ausflug in die KI sein würde, entwickelte sich schnell zu einem umfassenden und komplizierten Unterfangen, das weit mehr als nur ein oberflächliches Hochladen von Daten erforderte. Es wurde zu einem tiefen Eintauchen in die Feinheiten der KI, der natürlichen Sprachverarbeitung und des Wissensmanagements.
Die zentrale Herausforderung, vor der ich stand, bestand nicht nur darin, Informationen zu speichern, sondern der KI beizubringen, diese Informationen so zu verstehen, zu kontextualisieren und genau abzurufen, dass sie die Tiefe und Nuancierung meiner ursprünglichen Inhalte widerspiegeln. Dies erforderte einen vielschichtigen Ansatz, da ich feststellte, dass einfache Methoden der Datenspeicherung und -abfrage für die Komplexität der Fragen, die ich Fabrice AI stellen wollte, nicht ausreichten.
Die Reise führte mich durch eine breite Palette von Ansätzen, von den ersten Versuchen mit Vektorsuchindizes bis hin zu fortgeschritteneren Methoden, die Wissensgraphen, Metadatenabfragen und maßgeschneiderte KI-Modelle umfassen. Jeder Ansatz hatte seine eigenen Stärken und Schwächen, und jeder lehrte mich etwas Neues über die Komplexität der KI und die Feinheiten des digitalen Wissensmanagements. Den technischen Weg, den ich eingeschlagen habe, werde ich im nächsten Blogbeitrag im Detail beschreiben.
Neben den technischen Problemen erwies sich auch die Erstellung einer umfassenden Wissensdatenbank als Herausforderung. In der Anfangsphase, in der ich die Genauigkeit der KI testete, wurde mir klar, dass die detailliertesten und genauesten Antworten auf einige Fragen diejenigen waren, die ich in Videointerviews oder Podcasts gegeben hatte. Um genau zu sein, musste die Wissensdatenbank alle meine Beiträge, Videointerviews, Podcasts, PowerPoint-Präsentationen, Bilder und PDF-Dokumente enthalten.
Ich begann mit der Transkription des gesamten Inhalts. Da die automatischen Transkriptionen anfangs nur ungefähr sind, musste ich sicherstellen, dass die KI den Inhalt versteht. Das hat viel Zeit in Anspruch genommen, da ich die Antworten für jeden einzelnen transkribierten Inhalt testen musste.
Obwohl die Transkriptionen mich von dem anderen Sprecher trennten, dachte die KI zunächst, dass 100% der gesprochenen Inhalte von mir stammten, was eine Menge weiteres Training erforderte, um sicherzustellen, dass sie beide Sprecher bei allen Inhalten korrekt unterscheiden konnte. Außerdem wollte ich, dass die KI von Fabrice den neueren Inhalten mehr Gewicht gibt. Als ich das zum ersten Mal ausprobierte, verwendete sie natürlich das Datum, an dem ich den Inhalt auf den LLM hochgeladen hatte, und nicht das Datum, an dem ich den Artikel ursprünglich veröffentlicht hatte, was weitere Anpassungen erforderte.
Der Vollständigkeit halber habe ich auch das Wissen in den Folien, die ich im Blog geteilt habe, transkribiert, indem ich das OCR-Modell in Azure für die Umwandlung von Bildern in Text verwendet und die Dateien dann in die Wissensdatenbank des GPT-Assistenten hochgeladen habe. Ebenso lud ich PDFs aus der Mediathek von WordPress herunter und lud sie in die Wissensdatenbank hoch.
Während des Betatests ist mir aufgefallen, dass viele meiner Freunde persönliche Fragen gestellt haben, die im Blog nicht behandelt wurden. Ich bin gespannt, welche Art von Fragen die Leute in den nächsten Wochen stellen werden. Ich werde die Antworten vervollständigen, falls sie mit den vorhandenen Inhalten in meinem Blog nicht gefunden werden können. Beachten Sie, dass ich die Antworten von Fabrice AI absichtlich auf den Inhalt des Blogs beschränke, damit Sie wirklich Fabrice AI erhalten und nicht eine Mischung aus Fabrice AI und Chat GPT.
Es ist erwähnenswert, dass ich einen langwierigen Weg genommen habe, um hierher zu gelangen. Ich begann mit GPT3, war aber von den Ergebnissen enttäuscht. Es verwendete immer wieder die falschen Quellen, um die Fragen zu beantworten, obwohl einige Blogbeiträge genau die Antwort auf die gestellte Frage enthielten. Obwohl ich zig Stunden damit verbracht habe, die richtigen Inhalte zu verwenden (worauf ich im nächsten Blogbeitrag eingehen werde), habe ich nie Ergebnisse erhalten, mit denen ich zufrieden war.
Die Dinge verbesserten sich mit GPT3.5, waren aber immer noch enttäuschend. Ich habe dann mit GPT Builder eine GPT-Anwendung im GPT Store erstellt. Sie funktionierte etwas besser und war billiger im Betrieb. Allerdings konnte ich sie nicht auf meiner Website zum Laufen bringen, und sie war nur für bezahlte Abonnenten von Chat GPT verfügbar, was ich als zu einschränkend empfand. Unabhängig davon gefiel mir die Qualität der Antworten nicht und ich fühlte mich nicht wohl dabei, sie für die Öffentlichkeit freizugeben.
Der Durchbruch kam mit der Veröffentlichung von GPT Assistants mit dem Modell 4o. Ohne dass ich ihm sagen musste, welche Inhalte er verwenden sollte, fing er an, es selbst herauszufinden, und alles funktionierte einfach besser. Ich habe den Ansatz der GPT-Anwendung aufgegeben und bin zur Verwendung der API zurückgekehrt, so dass ich sie in den Blog einbetten konnte. Der Vollständigkeit halber habe ich auch Gemini getestet, zog aber die Antworten von GPT4o vor.
Ich veröffentliche vorerst eine reine Textversion. Sie enthält eine Voice-to-Text-Funktion, damit Sie Ihre Fragen per Stimme stellen können. Ich spiele mit dem Gedanken, eine interaktive Version zu programmieren, die aussieht und sich anhört wie ich und mit der Sie ein Gespräch führen können. Ich habe einen funktionierenden Prototyp, bin aber mit den Ergebnissen und den möglichen Kosten noch nicht zufrieden. Ich möchte sicherstellen, dass er in der ersten Person spricht, wirklich wie ich aussieht und klingt und mich nicht ein Vermögen kostet.
Wir werden sehen, wie weit ich in den kommenden Monaten komme, aber es könnte sinnvoll sein, auf GPT5 zu warten. Im Nachhinein betrachtet hätte ich Hunderte von Arbeitsstunden gespart, wenn ich einfach auf GPT4o gewartet hätte, um Fabrice AI zu entwickeln. Andererseits war die Untersuchung ein Teil der Sache, und sie war super interessant.
In der Zwischenzeit spielen Sie bitte mit Fabrice AI und lassen Sie mich wissen, was Sie davon halten!