

























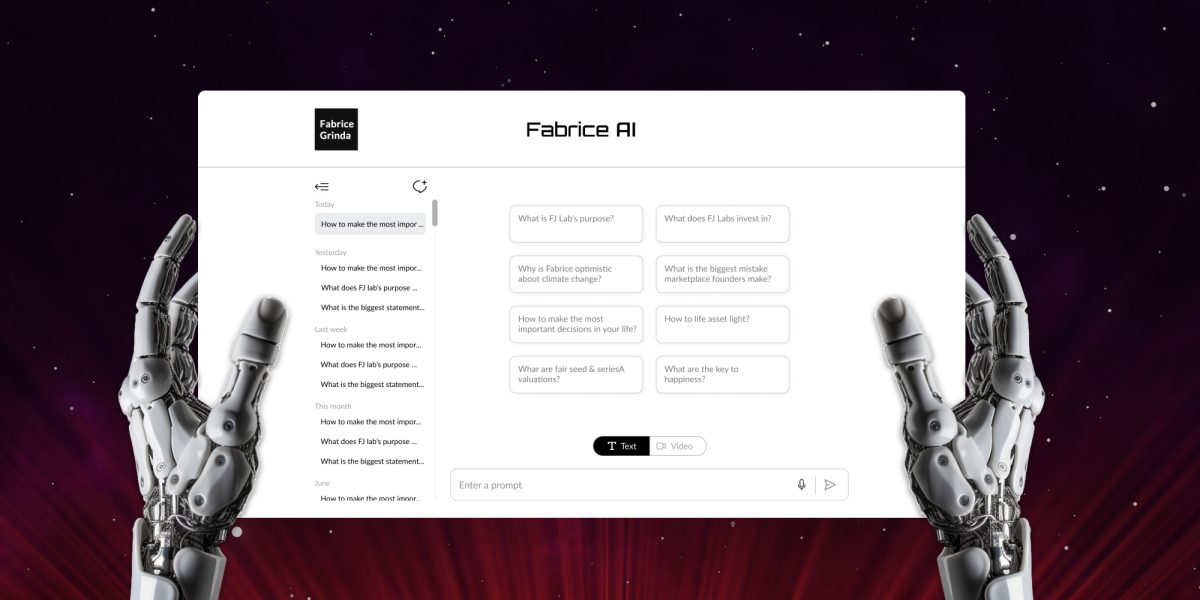
Fabrice AI est une représentation numérique de mes pensées basée sur l’ensemble du contenu de mon blog. Il se veut un assistant interactif et intelligent capable de comprendre et de répondre à des requêtes complexes avec nuance et précision.
Fabrice AI a commencé comme une expérience, une quête personnelle pour explorer le potentiel de l’intelligence artificielle en créant une version numérique des connaissances étendues que j’ai partagées au fil des ans. Au départ, je voyais cela comme un projet simple, quelque chose qui pouvait être réalisé en quelques heures. Le plan était simple : télécharger mon contenu dans l’API d’OpenAI et permettre à l’IA d’interagir avec lui, créant ainsi un assistant accessible et intelligent capable de fournir des réponses nuancées basées sur la richesse des informations que j’avais partagées.
Cependant, alors que je m’embarquais dans ce voyage, il est rapidement devenu évident que la tâche était bien plus complexe que je ne l’avais anticipé. Le projet, que je pensais être une brève incursion dans l’IA, s’est rapidement transformé en une entreprise complète et complexe, nécessitant bien plus qu’un simple téléchargement superficiel de données. Il s’est transformé en une plongée profonde dans les subtilités de l’IA, du traitement du langage naturel et de la gestion des connaissances.
Le défi principal auquel j’ai été confronté n’était pas seulement de stocker l’information, mais aussi d’apprendre à l’IA à comprendre, à contextualiser et à retrouver avec précision cette information d’une manière qui reflète la profondeur et la nuance de mon contenu original. Cela a nécessité une approche à multiples facettes, car j’ai découvert que les méthodes simples de stockage et de récupération des données étaient insuffisantes pour la complexité des questions que je voulais que Fabrice AI traite.
Ce voyage m’a fait découvrir un large éventail d’approches, depuis les premières tentatives d’utilisation d’indices de recherche vectoriels jusqu’à des méthodes plus avancées impliquant des graphes de connaissances, la recherche de métadonnées et des modèles d’IA personnalisés. Chaque approche avait ses propres forces et faiblesses, et chacune m’a appris quelque chose de nouveau sur les complexités de l’IA et les nuances de la gestion des connaissances numériques. Je décrirai en détail le chemin technique emprunté dans le prochain billet de blog.
Au-delà des problèmes techniques rencontrés, la création d’une base de connaissances exhaustive s’est également avérée difficile. Au cours des premières phases de test de la précision de l’IA, je me suis rendu compte que les réponses les plus détaillées et les plus précises à certaines questions étaient celles que j’avais données lors d’entretiens vidéo ou de podcasts. Pour être précise, la base de connaissances devait inclure tous mes articles, interviews vidéo, podcasts, présentations PowerPoint, images et documents PDF.
J’ai commencé par transcrire tout le contenu. Étant donné que les transcriptions automatiques sont approximatives au départ, je devais m’assurer que l’IA comprenait le contenu. Cela a pris beaucoup de temps, car je devais tester les réponses pour chaque élément du contenu transcrit.
Même si les transcriptions me séparaient de l’autre locuteur, l’IA a d’abord pensé que 100% du contenu parlé était le mien, ce qui a nécessité beaucoup d’entraînement supplémentaire pour s’assurer qu’elle pouvait différencier correctement les deux locuteurs sur l’ensemble du contenu. Je voulais aussi que l’IA de Fabrice donne plus de poids au contenu récent. Bien sûr, la première fois que j’ai essayé, l’IA a utilisé la date à laquelle j’ai téléchargé le contenu sur le LLM plutôt que la date à laquelle j’ai posté l’article à l’origine, ce qui a nécessité d’autres ajustements.
Dans un souci d’exhaustivité, j’ai également transcrit les connaissances contenues dans les diapositives que je partageais sur le blog en utilisant le modèle OCR d’Azure pour la conversion image-texte, puis j’ai téléchargé les fichiers dans la base de connaissances de l’assistant GPT. De même, j’ai téléchargé des PDF depuis la médiathèque de WordPress et les ai téléchargés dans la base de connaissances.
Pendant le test bêta, j’ai remarqué que beaucoup de mes amis posaient des questions personnelles qui n’étaient pas couvertes par le blog. J’attends de voir le type de questions que les gens poseront au cours des prochaines semaines. Je compléterai les réponses au cas où elles ne pourraient pas être trouvées dans le contenu existant de mon blog. Notez que je limite intentionnellement les réponses de Fabrice AI au contenu du blog, de sorte que vous obtenez vraiment Fabrice AI et non un mélange de Fabrice AI et de Chat GPT.
Il convient de préciser que j’ai emprunté un long chemin pour en arriver là. J’ai commencé par utiliser GPT3, mais j’ai été déçu par les résultats. Il n’arrêtait pas d’utiliser les mauvaises sources pour répondre aux questions, même si certains articles de blog contenaient exactement la réponse à la question posée. Malgré des dizaines d’heures de travail sur la question pour essayer d’utiliser le bon contenu (ce que j’aborderai dans le prochain billet), je n’ai jamais obtenu de résultats satisfaisants.
La situation s’est améliorée avec GPT3.5, mais elle est restée décevante. J’ai alors créé une application GPT dans le GPT Store à l’aide de GPT Builder. Elle fonctionnait un peu mieux et était moins chère à utiliser. Cependant, je n’ai pas réussi à la faire fonctionner sur mon site web, et elle n’était disponible que pour les abonnés payants de Chat GPT, ce qui me semblait trop restrictif. Quoi qu’il en soit, je n’aimais pas la qualité des réponses et je ne me sentais pas à l’aise à l’idée de le mettre à la disposition du public.
La percée s’est produite avec la sortie des assistants GPT utilisant le modèle 4o. Sans que j’aie besoin de lui dire quel contenu utiliser, il a commencé à se débrouiller tout seul et tout a mieux fonctionné. J’ai abandonné l’approche de l’application GPT et je suis revenu à l’utilisation de l’API pour pouvoir l’intégrer au blog. Dans un souci d’exhaustivité, j’ai également testé Gemini, mais j’ai préféré les réponses données par GPT4o.
Pour l’instant, je propose une version texte uniquement. Elle comprend une fonction de synthèse vocale qui vous permet de poser vos questions par la voix. Je réfléchis à quelques moyens de coder une version interactive qui me ressemble et avec laquelle vous pourriez avoir une conversation. J’ai un prototype fonctionnel, mais je suis loin d’être satisfait des résultats et du coût potentiel. Je veux m’assurer qu’il parle à la première personne, qu’il me ressemble vraiment et que son fonctionnement ne me coûte pas un bras et une jambe.
Nous verrons si je progresse dans les mois à venir, mais il pourrait être judicieux d’attendre le GPT5. Avec le recul, j’aurais économisé des centaines d’heures de travail si j’avais attendu le GPT4o pour développer Fabrice AI. Encore une fois, l’enquête faisait partie de l’objectif, et c’était super intéressant.
En attendant, jouez avec Fabrice AI et faites-moi savoir ce que vous en pensez !