

























Memperkenalkan Fabrice AI
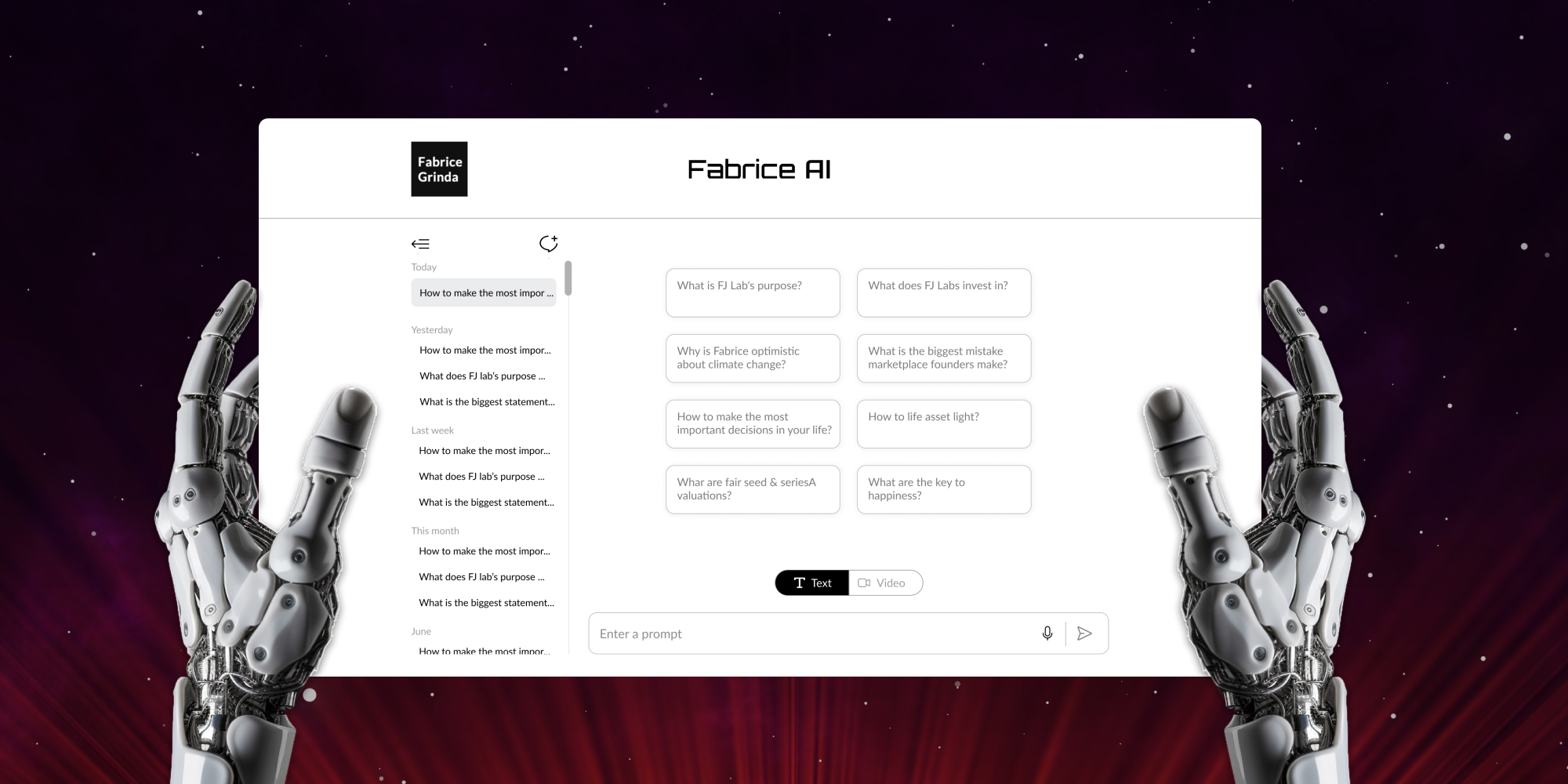
Fabrice AI adalah representasi digital dari pemikiran saya berdasarkan semua konten blog saya. Ini dimaksudkan untuk menjadi asisten yang interaktif dan cerdas yang mampu memahami dan merespons pertanyaan yang kompleks dengan nuansa dan akurasi.
Fabrice AI dimulai sebagai sebuah eksperimen, sebuah pencarian pribadi untuk mengeksplorasi potensi kecerdasan buatan dengan menciptakan versi digital dari pengetahuan luas yang telah saya bagikan selama bertahun-tahun. Awalnya, saya membayangkan ini sebagai proyek yang mudah, sesuatu yang dapat diselesaikan dalam hitungan jam. Rencananya sederhana: mengunggah konten saya ke API OpenAI dan mengizinkan AI untuk berinteraksi dengannya, sehingga menciptakan asisten cerdas yang mudah diakses yang dapat memberikan jawaban bernuansa berdasarkan kekayaan informasi yang telah saya bagikan.
Namun, ketika saya memulai perjalanan ini, dengan cepat menjadi jelas bahwa tugas ini jauh lebih kompleks daripada yang saya perkirakan. Proyek ini, yang saya pikir akan menjadi sebuah percobaan singkat dalam AI, dengan cepat berkembang menjadi sebuah usaha yang komprehensif dan rumit, yang membutuhkan lebih dari sekadar mengunggah data yang dangkal. Hal ini berubah menjadi penyelaman yang mendalam ke dalam seluk-beluk AI, pemrosesan bahasa alami, dan manajemen pengetahuan.
Tantangan utama yang saya hadapi bukan hanya tentang menyimpan informasi, tetapi juga tentang mengajari AI untuk memahami, mengontekstualisasikan, dan secara akurat mengambil informasi tersebut dengan cara yang mencerminkan kedalaman dan nuansa konten asli saya. Hal ini membutuhkan pendekatan dari berbagai sisi, karena saya menemukan bahwa metode penyimpanan dan pengambilan data yang sederhana tidak cukup untuk kompleksitas pertanyaan yang saya inginkan untuk ditangani oleh Fabrice AI.
Perjalanan ini membawa saya melalui berbagai macam pendekatan, mulai dari upaya awal menggunakan indeks pencarian vektor hingga metode yang lebih canggih yang melibatkan grafik pengetahuan, pengambilan metadata, dan model AI yang dibuat khusus. Setiap pendekatan memiliki kekuatan dan kelemahannya masing-masing, dan masing-masing mengajarkan saya sesuatu yang baru tentang kompleksitas AI dan nuansa manajemen pengetahuan digital. Saya akan menjelaskan secara rinci jalur teknis yang diambil dalam posting blog berikutnya.
Di luar masalah teknis yang dihadapi, menghasilkan basis pengetahuan yang lengkap juga terbukti menantang. Pada fase awal pengujian keakuratan AI, saya menyadari bahwa jawaban yang paling rinci dan akurat untuk beberapa pertanyaan adalah jawaban yang saya berikan dalam wawancara video atau podcast. Agar akurat, saya memerlukan basis pengetahuan untuk menyertakan semua tulisan, wawancara video, podcast, presentasi PowerPoint, gambar, dan dokumen PDF saya.
Saya mulai dengan mentranskripsikan semua konten. Karena transkripsi otomatis merupakan perkiraan, saya harus memastikan bahwa AI memahami kontennya. Hal ini membutuhkan waktu yang lama karena saya harus menguji jawaban untuk setiap bagian konten yang ditranskripsikan.
Meskipun transkripsi memisahkan saya dari pembicara lain, AI pertama kali mengira 100% konten yang diucapkan adalah milik saya, yang membutuhkan banyak pelatihan lebih lanjut untuk memastikan AI dapat membedakan kedua pembicara dengan benar pada semua konten. Saya juga ingin agar AI Fabrice memberi bobot lebih pada konten terbaru. Tentu saja, saat pertama kali saya mencobanya, AI menggunakan tanggal saat saya mengunggah konten ke LLM, bukan tanggal saat saya memposting artikel tersebut, yang memerlukan penyesuaian lebih lanjut.
Demi kelengkapan, saya juga menyalin pengetahuan dalam slide yang saya bagikan di blog dengan menggunakan model OCR di Azure untuk konversi gambar ke teks kemudian mengunggah file ke basis pengetahuan asisten GPT. Demikian juga, saya mengunduh PDF dari perpustakaan media WordPress dan mengunggahnya ke basis pengetahuan.
Selama pengujian beta, saya memperhatikan bahwa banyak teman saya mengajukan pertanyaan pribadi yang tidak tercakup di blog. Saya menunggu untuk melihat jenis pertanyaan yang diajukan orang selama beberapa minggu ke depan. Saya akan melengkapi jawabannya jika tidak dapat ditemukan dengan konten yang ada di blog saya. Perhatikan bahwa saya sengaja membatasi jawaban Fabrice AI pada konten yang ada di blog, sehingga Anda benar-benar mendapatkan Fabrice AI dan bukan campuran Fabrice AI dan Chat GPT.
Perlu disebutkan bahwa saya menempuh jalan yang bertele-tele untuk sampai ke sini. Saya mulai dengan menggunakan GPT3 tetapi kecewa dengan hasilnya. Ia terus menggunakan sumber yang salah untuk menjawab pertanyaan meskipun beberapa posting blog memiliki jawaban yang tepat untuk pertanyaan yang diajukan. Meskipun telah menghabiskan waktu puluhan jam untuk mengatasi masalah ini dan mencoba membuatnya menggunakan konten yang tepat (yang akan saya bahas di posting blog berikutnya), saya tidak pernah mendapatkan hasil yang memuaskan.
Banyak hal membaik dengan GPT3.5 tetapi masih mengecewakan. Saya kemudian membuat aplikasi GPT di GPT Store menggunakan GPT Builder. Aplikasi ini bekerja sedikit lebih baik dan lebih murah untuk dioperasikan. Namun, saya tidak dapat menjalankannya di situs web saya, dan hanya tersedia untuk pelanggan berbayar Chat GPT yang menurut saya terlalu membatasi. Terlepas dari itu, saya tidak menyukai kualitas jawabannya dan tidak nyaman untuk merilisnya ke publik.
Terobosan ini datang dengan dirilisnya Asisten GPT yang menggunakan model 4o. Tanpa saya harus memberitahukan konten mana yang harus digunakan, ia mulai mengetahuinya dengan sendirinya dan semuanya berjalan dengan lebih baik. Saya meninggalkan pendekatan aplikasi GPT dan kembali menggunakan API sehingga saya bisa menyematkannya di blog. Demi kelengkapan, saya juga menguji Gemini, tetapi lebih memilih jawaban yang diberikan oleh GPT4o.
Saya merilis versi teks saja untuk saat ini. Versi ini menyertakan fitur suara-ke-teks sehingga Anda bisa mengajukan pertanyaan melalui suara. Saya sedang mencoba-coba beberapa cara untuk membuat kode versi interaktif yang terlihat dan terdengar seperti saya sehingga Anda bisa bercakap-cakap. Saya memiliki prototipe yang berfungsi namun masih jauh dari puas dengan hasil dan potensi biayanya. Saya ingin memastikan bahwa aplikasi ini dapat berbicara sebagai orang pertama, benar-benar terlihat dan terdengar seperti saya, dan tidak memerlukan biaya yang mahal untuk mengoperasikannya.
Kita lihat saja seberapa besar kemajuan yang saya capai dalam beberapa bulan ke depan, tetapi mungkin masuk akal untuk menunggu GPT5. Jika dipikir-pikir, saya bisa menghemat ratusan jam kerja jika saya menunggu GPT4o untuk mengembangkan Fabrice AI. Sekali lagi, investigasi adalah bagian dari intinya, dan itu sangat menarik.
Sementara itu, silakan bermain dengan Fabrice AI dan beritahu saya pendapat Anda!