

























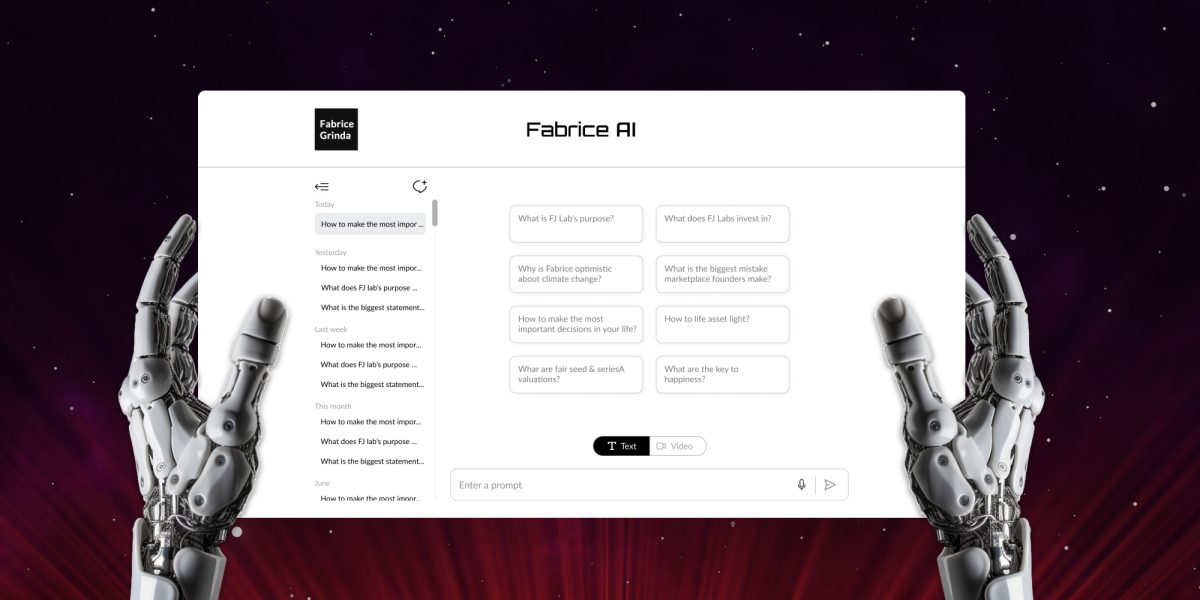
Fabrice AI – це цифрове представлення моїх думок, засноване на всьому вмісті мого блогу. Він має бути інтерактивним, розумним помічником, здатним розуміти і відповідати на складні запити з нюансами і точністю.
Fabrice AI починався як експеримент, особисте прагнення дослідити потенціал штучного інтелекту, створивши цифрову версію великих знань, якими я ділився протягом багатьох років. Спочатку я уявляв собі це як простий проект, який можна було б завершити за кілька годин. План був простий: завантажити мій контент в API OpenAI і дозволити штучному інтелекту взаємодіяти з ним, таким чином створивши доступного, розумного помічника, який міг би надавати нюансовані відповіді на основі багатства інформації, якою я поділився.
Однак, коли я розпочав цю подорож, швидко стало зрозуміло, що завдання набагато складніше, ніж я очікував. Проект, який, як я думав, буде коротким експериментом зі штучним інтелектом, швидко перетворився на всеосяжну і складну роботу, що вимагала набагато більше, ніж просто поверхневе завантаження даних. Це перетворилося на глибоке занурення в тонкощі штучного інтелекту, обробки природної мови та управління знаннями.
Основна проблема, з якою я зіткнувся, полягала не просто в зберіганні інформації, а в тому, щоб навчити штучний інтелект розуміти, контекстуалізувати і точно видобувати цю інформацію таким чином, щоб вона відображала глибину і нюанси мого оригінального контенту. Це вимагало багатогранного підходу, оскільки я виявив, що простих методів зберігання та пошуку даних недостатньо для вирішення складних питань, з якими я хотів, щоб Fabrice AI впорався.
Ця подорож провела мене через широкий спектр підходів, від початкових спроб використання векторних пошукових індексів до більш просунутих методів, що включають графіки знань, пошук метаданих та власні моделі ШІ. Кожен підхід мав свої сильні та слабкі сторони, і кожен навчив мене чогось нового про складнощі ШІ та нюанси управління цифровими знаннями. Я детально опишу технічний шлях у наступному блозі.
Окрім технічних проблем, створення вичерпної бази знань також виявилося складним завданням. На ранніх етапах тестування точності штучного інтелекту я зрозумів, що найдетальніші та найточніші відповіді на деякі питання я давав у відеоінтерв’ю або подкастах. Щоб бути точним, мені потрібно було, щоб база знань включала всі мої пости, відеоінтерв’ю, подкасти, презентації PowerPoint, зображення та PDF-документи.
Я почав з транскрибування всього контенту. Враховуючи, що автоматичні транскрипції спочатку є приблизними, я повинен був переконатися, що ШІ розуміє зміст. Це зайняло багато часу, оскільки мені довелося тестувати відповіді для кожного фрагмента транскрибованого контенту.
Незважаючи на те, що транскрипція відділяла мене від іншого спікера, штучний інтелект спочатку вважав, що 100% усного контенту належить мені, що вимагало значних додаткових тренувань, щоб переконатися, що він може правильно розрізняти обох спікерів у всьому контенті. Я також хотів, щоб Фабріс ШІ надавав більшої ваги нещодавньому контенту. Звичайно, коли я вперше спробував це зробити, він використовував дату, коли я завантажив контент на LLM, а не дату, коли я опублікував статтю, що вимагало подальших налаштувань.
Для вичерпності я також переписав знання у слайди, якими поділився в блозі, використовуючи модель OCR в Azure для перетворення зображення в текст, а потім завантажив файли до бази знань GPT assistant. Так само я завантажив PDF-файли з медіатеки WordPress і завантажив їх до бази знань.
Під час бета-тестування я помітив, що багато моїх друзів ставили особисті питання, які не були висвітлені в блозі. Я з нетерпінням чекаю на запитання, які люди будуть ставити протягом наступних кількох тижнів. Я доповню відповіді, якщо їх не можна буде знайти в існуючому контенті мого блогу. Зверніть увагу, що я навмисно обмежую відповіді Fabrice AI контентом блогу, щоб ви дійсно отримали Fabrice AI, а не суміш Fabrice AI і Chat GPT.
Варто зазначити, що я пройшов довгий шлях, щоб потрапити сюди. Я почав з використання GPT3, але був розчарований результатами. Він продовжував використовувати неправильні джерела для відповідей на запитання, хоча деякі пости в блогах містили саме ту відповідь, про яку йшлося в запитанні. Незважаючи на десятки годин роботи над проблемою, намагаючись змусити його використовувати правильний контент (про що я розповім у наступному блозі), я так і не отримав результатів, які б мене задовольнили.
З GPT3.5 ситуація покращилася, але все одно була невтішною. Тоді я створив GPT-додаток у GPT Store за допомогою GPT Builder. Він працював трохи краще і був дешевшим в експлуатації. Однак я не зміг запустити його на своєму веб-сайті, і він був доступний лише для платних передплатників Chat GPT, що, на мою думку, було надто обмежуючим фактором. Незважаючи на це, мені не подобалася якість відповідей, і мені було незручно викладати їх у відкритий доступ.
Прорив стався з випуском GPT Assistants, що використовує модель 4o. Мені не потрібно було вказувати йому, який контент використовувати, він просто почав розбиратися в цьому самостійно, і все стало працювати краще. Я відмовився від підходу GPT-додатків і повернувся до використання API, щоб вбудовувати його в блог. Для повноти картини я також протестував Gemini, але віддав перевагу відповідям, наданим GPT4o.
Наразі я випускаю лише текстову версію. Вона включає в себе функцію перетворення голосу в текст, щоб ви могли ставити свої запитання голосом. Я випробовую кілька способів створення інтерактивної версії, яка виглядатиме і звучатиме як я, і з якою можна буде вести розмову. У мене є робочий прототип, але я далеко не задоволений результатами і потенційною вартістю. Я хочу переконатися, що він говорить від першої особи, дійсно виглядає і звучить як я, і не коштує мені руки і ноги.
Побачимо, наскільки мені вдасться досягти прогресу в найближчі місяці, але, можливо, є сенс дочекатися GPT5. Озираючись назад, я б заощадив сотні годин роботи, якби дочекався GPT4o, щоб розробити Fabrice AI. Знову ж таки, дослідження було частиною справи, і воно було надзвичайно цікавим.
А поки що, будь ласка, пограйте з Fabrice AI і дайте мені знати, що ви про нього думаєте!