

























在上一篇文章《Fabrice AI:技术之旅》中,我介绍了我们构建 Fabrice AI的整个过程。 一开始,我使用 Chat GPT 3 和 3.5。 由于对结果感到失望,我尝试使用Langchain Framework在其基础上构建自己的人工智能模型,后来他们开始使用向量数据库,并使用 4o 大幅提高了结果,于是我又回到了 Chat GPT。
以下是当前训练 Fabrice AI 的流程:
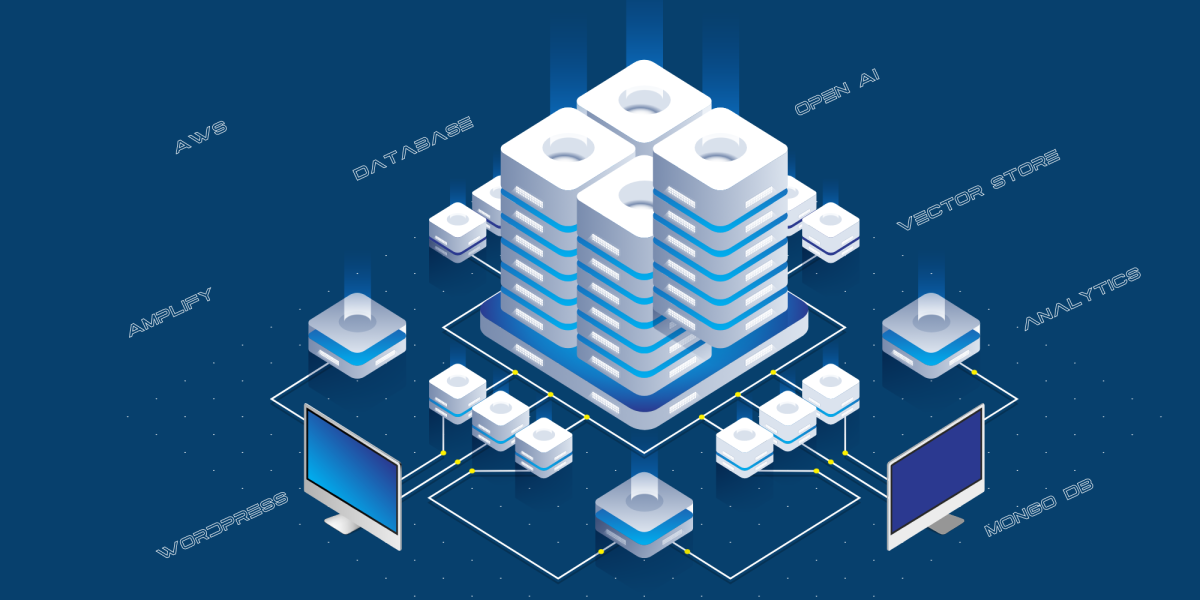
- 训练数据(博客文章、Youtube URL、播客 URL、PDF URL 和图片 URL)存储在我们的WordPress数据库中。
- 我们提取数据并对其进行结构化处理。
- 我们将结构化数据提供给 Open AI,供其使用Assistants API 进行训练。
- 然后,Open AI 会创建一个矢量存储数据库并进行存储。
下面是一个结构化数据的示例。 每个内容都有自己的 JSON 文件。 我们确保不会超过 32,000 个代币的上限。
{
“id”:”1”,
“日期”:” “,
“link”:”https://fabricegrinda.com/”、
“标题”:{
“呈现”:”法布里斯人工智能是什么?”
},
“类别”:”关于法布里斯
“featured_media”(特色媒体):”https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”、
“other_media”(其他媒体):””,
“知识类型”:”博客”、
“contentUpdated”(内容更新):”法布里斯人工智能是法布里斯思想的数字化呈现,基于他的博客文章以及使用 ChatGPT 转录的部分播客和访谈。鉴于许多转录内容并不完善,而且博客只是法布里斯个人的有限呈现,我们对不准确和遗漏的信息表示歉意。尽管如此,这是了解法布里斯对许多话题看法的良好起点”。
}
这是目前的技术实施情况:
- 面向消费者的网站由AWS Amplify 托管。
- 公共网站与 Open AI 之间的集成是通过 API 层完成的,该层作为 Python API 服务器托管在 AWS 上。
- 我们使用MongoDB作为日志,存储公众提出的所有问题、聊天 GPT 给出的答案以及来源的 URL。
- 我们使用各种脚本对来自博客、YouTube 等的数据进行结构化处理,然后传递给开放人工智能进行训练。
- 我们使用React 语音识别技术将语音询问转换为文本。
- 我们还使用 Google Analytics 跟踪网站流量。
值得注意的是,我们使用了两名助手:
- 一个用于回答问题。
- 一个用于获取元数据 URL,即在答案底部显示来源的具有原始内容的博客 URL。
下一步怎么办?
- 语音转文本改进
Open AI 的Whisper 文本语音模型比 React 更准确。 它还支持多种语言,并且擅长处理混合语言语音、口音和方言。 因此,我很有可能在未来几个月内转用它。 不过,它的设置比较复杂,可能需要一段时间。 你需要处理模型、管理依赖关系(如 Python、库),并确保有足够的硬件来实现高效性能。 此外,Whisper 并不是为直接在浏览器中使用而设计的。 在构建网络应用时,您需要创建一个后台服务来处理转录,这就增加了复杂性。
- 法布里斯人工智能头像
我想创建一个法布里斯人工智能头像,它的外形和声音都很像我,你可以与它进行对话。 我评估了D-iD,但发现它太贵了,不符合我的要求。Eleven Labs只支持语音。Synthesia很不错,但目前还不能实时创建视频。 最后我决定使用HeyGen,因为它的价格和功能都更合适。
我猜想,Open AI 迟早会推出自己的解决方案,这样我们的工作就白费了。 我对此很满意,如果开放式人工智能解决方案推出,我将转而使用它。 在现阶段,整个工作的重点是了解人工智能的可能性,以及需要做多少工作才能帮助我更好地了解这个领域。
- 自定义仪表板
现在,我需要运行 MongoDB 查询来获取当天的问答摘要。 我正在建立一个简单的仪表板,在这里我可以获得提取信息和简单的统计数据,如每种语言的查询次数、语音转文本请求的次数等。
- 其他数据来源
我们刚刚将FJ Labs 投资组合上传到 Fabrice AI。 现在,您可以询问某家公司是否属于投资组合的一部分。 Fabrice AI 会给出简短的公司介绍和网站链接。

鉴于 Fabrice AI 收到的许多个人问题都没有答案,我花了很多时间手动标记了我50 岁生日视频中的每一位发言人,以提供它所需的内容。

结论
在过去的十二个月里,我做了大量与人工智能相关的工作,似乎得出了一个明确的普遍结论:你等得越多,它就会变得越便宜、越简单、越好,开放人工智能也就越有可能提供它! 同时,如果您有任何问题,请告诉我。
