

























在上一篇文章《 Fabrice AI:技術之旅 》中,我解釋了我們構建 Fabrice AI 所經歷的循環過程。 我從使用 Chat GPT 3 和 3.5 開始。 對結果感到失望,我嘗試使用 Langchain 框架 在其上構建自己的 AI 模型,然後在他們開始使用向量資料庫並使用 4o 大幅改善結果後回到 Chat GPT。
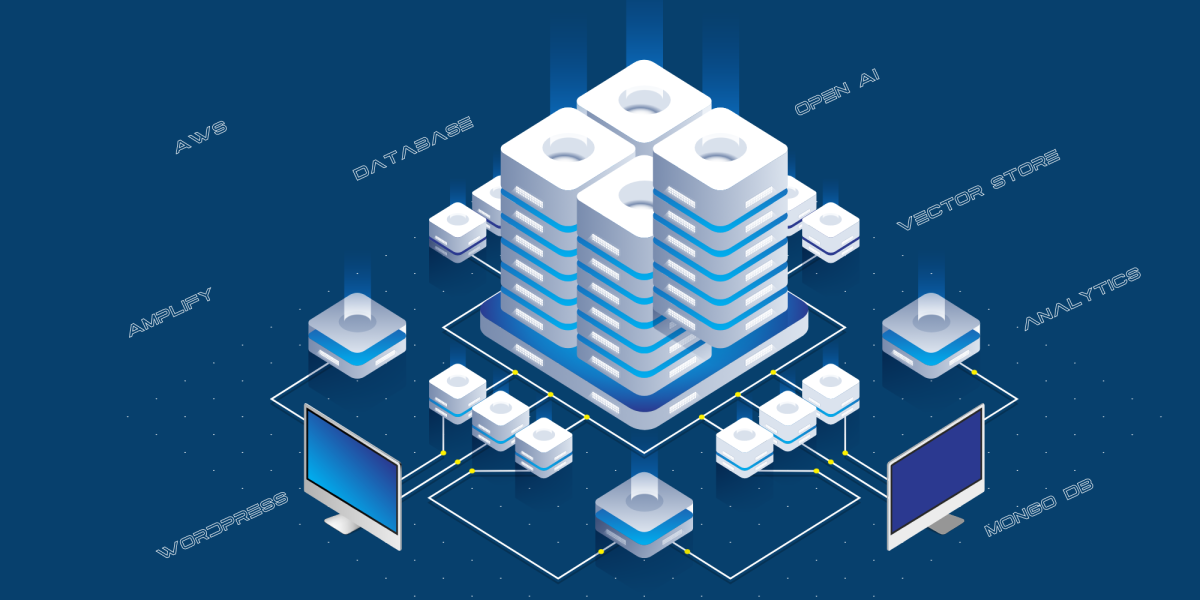
以下是當前訓練 Fabrice AI 的流程:
- 訓練數據(博客文章、Youtube URL、播客 URL、PDF URL 和圖像 URL)存儲在我們的 WordPress 資料庫中。
- 我們提取數據並對其進行結構化。
- 我們將結構化數據提供給 Open AI,以便使用 Assistants API 進行訓練。
- 然後,Open AI 會創建一個向量存儲資料庫並進行存儲。
下面是一段結構化數據的示例。 每個內容都有自己的 JSON 檔。 我們確保不超過 32,000 個令牌的限制。
{
“id”: “1”, /編號
“日期”: “ ”,
“link”:“https://fabricegrinda.com/”, @連結
“標題”: {
“rendered”: “什麼是 Fabrice AI?”
},
“Category”: “關於 Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“other_media”: “”,
“knowledge_type”: “博客”,
鑒於許多轉錄內容轉錄不完美,並且該博客只是 Fabrice 個人的有限代表,我們對不準確和缺失的資訊表示深表歉意。儘管如此,這是一個很好的起點,可以瞭解 Fabrice 對許多主題的看法。
}
這是當前的技術實現:
- 面向消費者的網站託管在 AWS Amplify 上。
- 公共網站和 Open AI 之間的整合是通過 API 層完成的,該層作為 Python API 伺服器託管在 AWS 上。
- 我們使用 MongoDB 作為日誌來存儲公眾提出的所有問題、Chat GPT 給出的答案以及來源的 URL。
- 我們使用各種腳本來構建來自博客、YouTube 等的數據,然後傳遞給 Open AI 進行訓練。
- 我們使用 React-Speech Recognition 將語音查詢轉換為文本。
- 我們還使用Google Analytics來跟蹤網站流量。
請務必注意,我們使用兩個助手:
- 一個用於回答問題。
- 一個用於獲取元數據 URL,即具有原始內容的博客 URL,用於在答案底部顯示源。
下一步是什麼?
- 語音轉文本改進
Open AI 的語音轉文本 Whisper 模型比 React 更準確。 它還支持開箱即用的多種語言,並且擅長處理混合語言語音、口音和方言。 因此,我很可能會在未來幾個月內轉向它。 也就是說,設置起來更複雜,因此可能需要一段時間。 您需要處理模型、管理依賴項(例如 Python、庫),並確保您有足夠的硬體來實現高效性能。 此外,Whisper 並不是為直接在瀏覽器中使用而設計的。 在構建 Web 應用程式時,您需要創建一個後端服務來處理轉錄,這會增加複雜性。
- Fabrice AI 虛擬形象
我想創建一個外觀和聲音都像我的 Fabrice AI Avatar,您可以與之交談。 我評估了 D-iD ,但發現它對我來說太貴了。 Eleven Labs 僅支持語音。 Synthesia 很棒,但目前無法實時創建視頻。 最後,鑒於更合適的定價和功能,我決定使用 HeyGen 。
我懷疑 Open AI 會在某個時候發佈自己的解決方案,所以這項工作將是徒勞的。 我對此感到滿意,如果它出現,我會切換到 Open AI 解決方案。 在這個階段,整個練習的重點是瞭解 AI 的可能性,以及需要做多少工作才能説明我更好地瞭解這個領域。
- 自定義儀錶板
現在,我需要運行 MongoDB 查詢來獲取當天問題和答案的摘要。 我正在構建一個簡單的儀錶板,在其中可以獲取有關每種語言的查詢數量、語音轉文本請求數量等的提取和簡單統計數據。
- 其他數據源
我們剛剛將 FJ Labs 產品組合 上傳到 Fabrice AI。 您現在可以詢問公司是否是投資組合的一部分。 Fabrice AI 回答了公司的簡短描述和指向其網站的連結。

鑒於 Fabrice AI 收到的許多個人問題都沒有答案,我花時間在我的 50歲 生日視頻 中手動標記了每位演講者,以提供所需的內容。

結論
根據我在過去 12 個月中在所有與 AI 相關的方面所做的所有工作,似乎有一個明確的普遍結論:您等待的時間越長,它就會變得越便宜、越容易、越好,Open AI 就越有可能提供它! 在此期間,如果您有任何問題,請告訴我。
