

























Fabrice AI: Aktuelle technische Umsetzung
Im letzten Beitrag, Fabrice AI: The Technical Journey, habe ich den Weg beschrieben, den wir bei der Entwicklung von Fabrice AI zurückgelegt haben, um einen Kreis zu schließen. Zunächst habe ich Chat GPT 3 und 3.5 verwendet. Enttäuscht von den Ergebnissen habe ich versucht, mit dem Langchain Framework mein eigenes KI-Modell darauf aufzubauen, bevor ich zu Chat GPT zurückkehrte, als sie anfingen, Vektordatenbanken zu verwenden und die Ergebnisse mit 4o massiv zu verbessern.
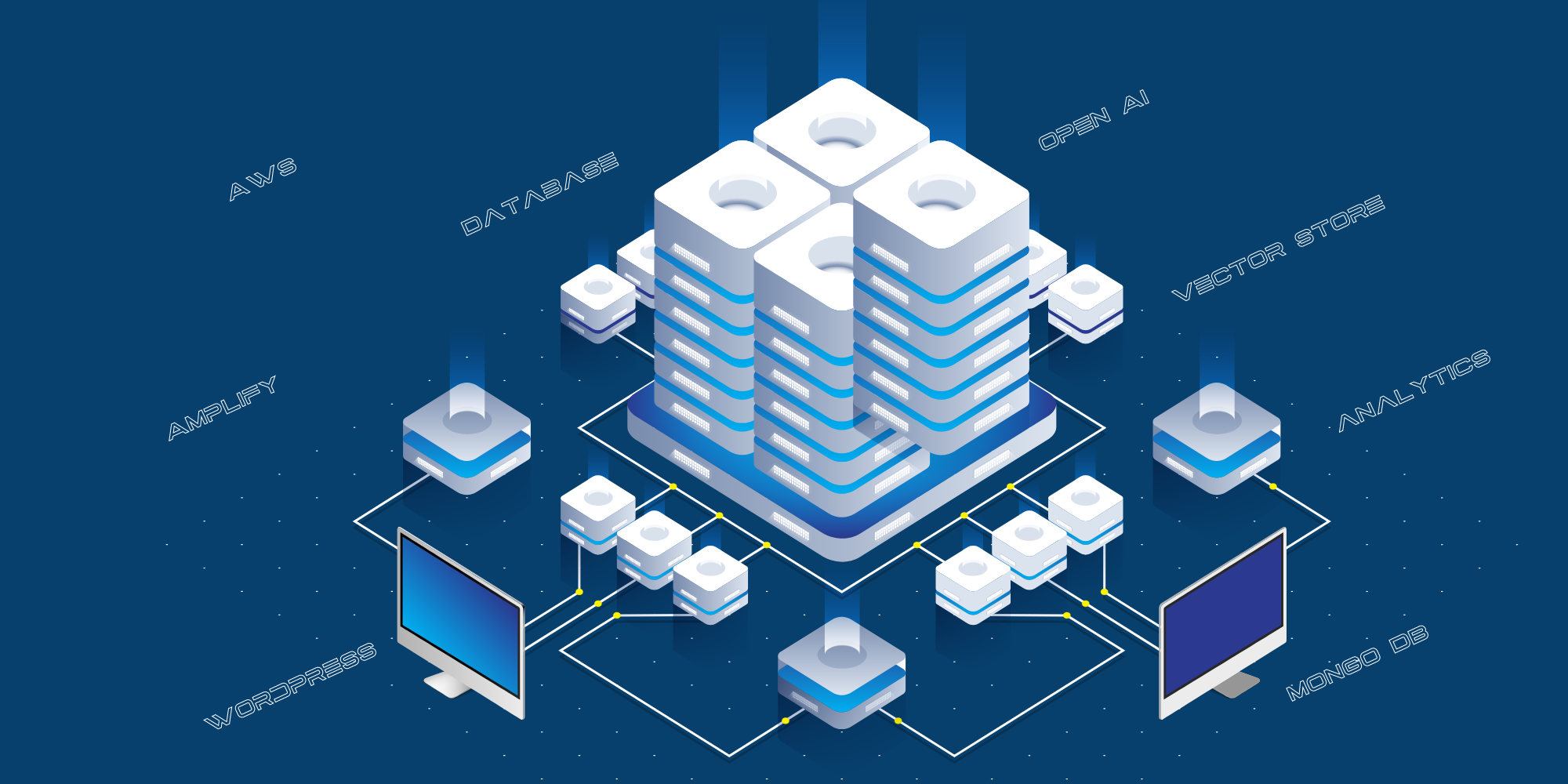
Hier ist der aktuelle Prozess für das Training von Fabrice AI:
- Die Trainingsdaten (Blogbeiträge, Youtube-URLs, Podcast-URLs, PDF-URLs und Bild-URLs) werden in unserer WordPress-Datenbank gespeichert.
- Wir extrahieren die Daten und strukturieren sie.
- Wir stellen Open AI die strukturierten Daten für das Training über die Assistenten-API zur Verfügung.
- Open AI erstellt dann eine Vektorspeicher-Datenbank und speichert sie.
Hier ist ein Beispiel für strukturierte Daten. Jeder Inhalt hat seine eigene JSON-Datei. Wir stellen sicher, dass das Limit von 32.000 Token nicht überschritten wird.
{
“id”: “1”,
“Datum”: ” “,
“link”: “https://fabricegrinda.com/”,
“Titel”: {
“gerendert”: “Was ist Fabrice AI?”
},
“Kategorie”: “Über Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“andere_medien”: “”,
“Wissen_Art”: “Blog”,
“contentUpdated”: “Fabrice AI ist eine digitale Darstellung von Fabrice’ Gedanken, die auf seinen Blog-Beiträgen und ausgewählten transkribierten Podcasts und Interviews mit ChatGPT basieren. Da viele der Transkriptionen unvollkommen transkribiert sind und der Blog nur eine begrenzte Darstellung der Person Fabrice ist, entschuldigen wir uns für Ungenauigkeiten und fehlende Informationen. Nichtsdestotrotz ist dies ein guter Ausgangspunkt, um Fabrice’ Gedanken zu vielen Themen zu erfahren.”
}
Das ist die aktuelle technische Umsetzung:
- Die Website für Verbraucher wird auf AWS Amplify gehostet.
- Die Integration zwischen der öffentlichen Website und Open AI erfolgt über eine API-Schicht, die auf AWS als Python-API-Server gehostet wird.
- Wir verwenden MongoDB als Protokoll, um alle von der Öffentlichkeit gestellten Fragen, die von Chat GPT gegebenen Antworten und die URLs der Quellen zu speichern.
- Wir verwenden verschiedene Skripte, um die Daten aus dem Blog, YouTube usw. zu strukturieren und an Open AI für das Training zu übergeben.
- Wir verwenden React-Speech Recognition, um Sprachanfragen in Text umzuwandeln.
- Wir verwenden auch Google Analytics, um den Website-Verkehr zu verfolgen.
Es ist wichtig zu wissen, dass wir zwei Assistenten einsetzen:
- Eine für die Beantwortung von Fragen.
- Eine, um Metadaten-URLs zu erhalten, die Blog-URLs, die den ursprünglichen Inhalt haben, um die Quellen am Ende der Antworten anzuzeigen.
Was nun?
- Verbesserungen bei Sprache-zu-Text
Das Whisper-Modell von Open AI für Sprache in Text ist genauer als React. Es unterstützt außerdem von Haus aus mehrere Sprachen und ist gut im Umgang mit gemischter Sprache, Akzenten und Dialekten. Daher werde ich in den kommenden Monaten höchstwahrscheinlich zu React wechseln. Allerdings ist die Einrichtung etwas komplexer, so dass es eine Weile dauern könnte. Sie müssen sich um das Modell kümmern, Abhängigkeiten verwalten (z. B. Python, Bibliotheken) und sicherstellen, dass Sie über ausreichend Hardware für eine effiziente Leistung verfügen. Außerdem ist Whisper nicht für die direkte Verwendung in Browsern konzipiert. Wenn Sie eine Webanwendung entwickeln, müssen Sie einen Backend-Dienst erstellen, um die Transkription zu verwalten, was die Komplexität erhöht.
- Fabrice AI Avatar
Ich möchte einen KI-Avatar von Fabrice erstellen, der aussieht und sich anhört wie ich und mit dem man eine Unterhaltung führen kann. Ich habe D-iD getestet, fand es aber viel zu teuer für meine Zwecke. Eleven Labs ist nur für die Stimme. Synthesia ist großartig, kann aber derzeit keine Videos in Echtzeit erstellen. Letztendlich habe ich mich aufgrund des günstigeren Preises und der besseren Funktionalität für HeyGen entschieden.
Ich vermute, dass Open AI irgendwann seine eigene Lösung herausbringen wird, so dass diese Arbeit umsonst gewesen sein wird. Damit kann ich gut leben und werde auf die Open AI-Lösung umsteigen, wenn sie kommt. In diesem Stadium geht es bei dieser ganzen Übung darum, zu lernen, was mit KI möglich ist und wie viel Arbeit es erfordert, damit ich den Bereich besser verstehe.
- Benutzerdefiniertes Dashboard
Im Moment muss ich eine MongoDB-Abfrage ausführen, um einen Auszug der Fragen und Antworten des Tages zu erhalten. Ich baue ein einfaches Dashboard, auf dem ich Extraktionen und einfache Statistiken über die Anzahl der Abfragen pro Sprache, die Anzahl der Sprache-zu-Text-Anfragen usw. abrufen kann.
- Zusätzliche Datenquellen
Wir haben gerade das FJ Labs Portfolio zu Fabrice AI hochgeladen. Sie können jetzt fragen, ob ein Unternehmen Teil des Portfolios ist. Fabrice AI antwortet mit einer kurzen Beschreibung des Unternehmens und einem Link zu seiner Website.

Angesichts der vielen persönlichen Fragen, die Fabrice AI erhielt und auf die sie keine Antworten hatte, habe ich mir die Zeit genommen, jeden Sprecher in meinem Video zum 50 . Geburtstag manuell zu markieren, um ihm den nötigen Inhalt zu geben.

Fazit
Bei all der Arbeit, die ich in den letzten zwölf Monaten in Sachen KI geleistet habe, scheint es eine klare, allgemeingültige Schlussfolgerung zu geben: Je länger Sie warten, desto billiger, einfacher und besser wird es, und desto wahrscheinlicher ist es, dass Open AI es anbieten wird! Lassen Sie mich in der Zwischenzeit wissen, wenn Sie Fragen haben.