

























Fabrice AI : Mise en œuvre technique actuelle
Dans le dernier article, Fabrice AI : The Technical Journey, j’ai expliqué le parcours que nous avons suivi pour construire Fabrice AI en faisant un tour complet. J’ai commencé par utiliser Chat GPT 3 et 3.5. Déçu par les résultats, j’ai essayé d’utiliser le Langchain Framework pour construire mon propre modèle d’IA, avant de revenir à Chat GPT lorsqu’ils ont commencé à utiliser des bases de données vectorielles et à améliorer massivement les résultats avec 4o.
Voici le processus actuel de formation de Fabrice AI :
- Les données de formation (articles de blog, URL de Youtube, URL de podcasts, URL de PDF et URL d’images) sont stockées dans notre base de données WordPress.
- Nous extrayons les données et les structurons.
- Nous fournissons les données structurées à Open AI pour la formation à l’aide de l’API Assistants.
- Open AI crée ensuite une base de données vectorielle et la stocke.
Voici un exemple de données structurées. Chaque élément de contenu a son propre fichier JSON. Nous veillons à ne pas dépasser la limite de 32 000 jetons.
{
« id » : « 1 »,
« date » : » « ,
« link » : « https://fabricegrinda.com/ »,
« title » : {
« rendu » : « Qu’est-ce que Fabrice AI ? »
},
« Catégorie » : « A propos de Fabrice »,
« featured_media » : « https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png »,
« other_media » : « »,
« knowledge_type » : « blog »,
« contentUpdated » : « Fabrice AI est une représentation numérique des pensées de Fabrice basée sur les articles de son blog et sur une sélection de podcasts et d’interviews transcrites à l’aide de ChatGPT. Étant donné que de nombreuses transcriptions sont imparfaites et que le blog n’est qu’une représentation limitée de Fabrice en tant qu’individu, nous nous excusons des inexactitudes et des informations manquantes. Néanmoins, il s’agit d’un bon point de départ pour obtenir les pensées de Fabrice sur de nombreux sujets. »
}
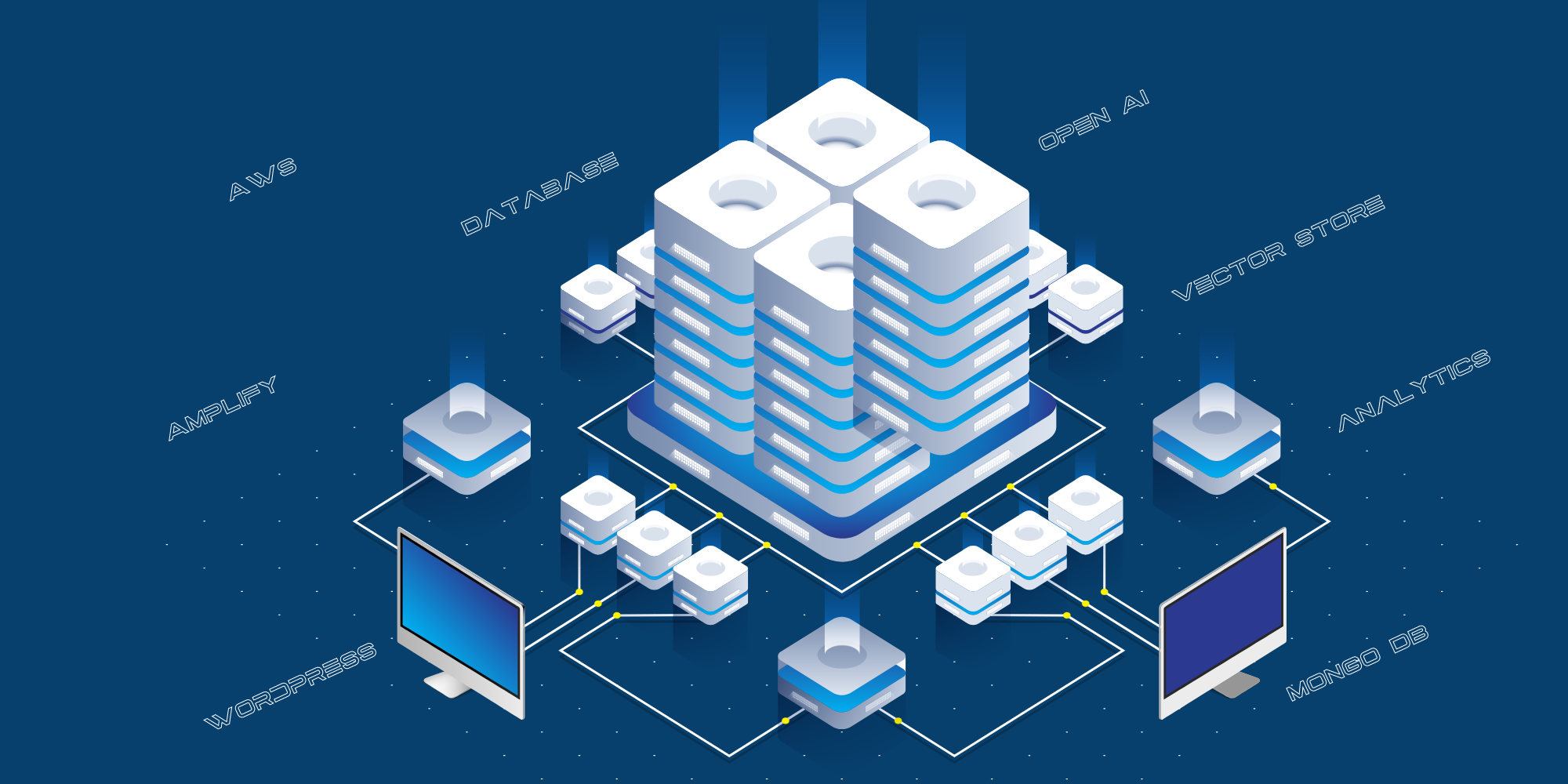
Il s’agit de la mise en œuvre technique actuelle :
- Le site web destiné aux consommateurs est hébergé sur AWS Amplify.
- L’intégration entre le site public et Open AI se fait par l’intermédiaire d’une couche API, hébergée sur AWS en tant que serveur API Python.
- Nous utilisons MongoDB comme journal pour stocker toutes les questions posées par le public, les réponses données par Chat GPT et les URL des sources.
- Nous utilisons divers scripts pour structurer les données provenant du blog, de YouTube, etc. afin de les transmettre à Open AI pour la formation.
- Nous utilisons la reconnaissance vocale React-Speech pour convertir les demandes vocales en texte.
- Nous utilisons également Google Analytics pour suivre le trafic sur le site web.
Il est important de noter que nous utilisons deux assistants :
- Un pour répondre aux questions.
- L’un pour obtenir les URL des métadonnées, les URL des blogs qui ont le contenu original pour afficher les sources au bas des réponses.
Quelle est la prochaine étape ?
- Amélioration de la synthèse vocale
Le modèle Whisper d’Open AI pour la conversion de la parole en texte est plus précis que React. Il prend également en charge plusieurs langues dès sa sortie de l’emballage et gère bien les langues mixtes, les accents et les dialectes. C’est pourquoi il est fort probable que je l’adopte dans les mois à venir. Cela dit, il est plus complexe à mettre en place, ce qui peut prendre un certain temps. Vous devez gérer le modèle, les dépendances (par exemple, Python, les bibliothèques), et vous assurer que vous avez suffisamment de matériel pour des performances efficaces. De plus, Whisper n’est pas conçu pour une utilisation directe dans les navigateurs. Lorsque vous construisez une application web, vous devez créer un service backend pour gérer la transcription, ce qui ajoute de la complexité.
- Fabrice AI Avatar
Je veux créer un Avatar Fabrice AI qui me ressemble et avec lequel vous pouvez avoir une conversation. J’ai évalué D-iD mais je l’ai trouvé beaucoup trop cher pour mes besoins. Eleven Labs est uniquement vocal. Synthesia est excellent mais ne permet pas de créer des vidéos en temps réel. Finalement, j’ai décidé d’utiliser HeyGen en raison de son prix et de ses fonctionnalités plus appropriés.
Je soupçonne qu’à un moment donné, Open AI publiera sa propre solution et que ce travail n’aura servi à rien. Cela ne me dérange pas et je passerai à la solution Open AI lorsqu’elle sera disponible. À ce stade, le but de cet exercice est d’apprendre ce qui est possible avec l’IA et la quantité de travail nécessaire pour m’aider à mieux comprendre l’espace.
- Tableau de bord personnalisé
Pour l’instant, je dois exécuter une requête MongoDB pour obtenir un extrait des questions et réponses de la journée. Je suis en train de construire un tableau de bord simple où je peux obtenir des extractions et des statistiques simples sur le nombre de requêtes par langue, le nombre de demandes de synthèse vocale, etc.
- Sources de données supplémentaires
Nous venons de télécharger le portefeuille de FJ Labs sur Fabrice AI. Vous pouvez maintenant demander si une entreprise fait partie du portefeuille. Fabrice AI vous répondra avec une courte description de la société et un lien vers son site web.

Etant donné le nombre de questions personnelles que Fabrice AI recevait et auxquelles il n’avait pas de réponse, j’ai pris le temps de taguer manuellement chaque intervenant dans ma vidéo d’anniversaire des 50 ans pour lui donner le contenu dont il avait besoin.

Conclusion
Avec tout le travail que j’ai effectué au cours des douze derniers mois sur tout ce qui concerne l’IA, il semble y avoir une conclusion universelle claire : plus vous attendez, moins c’est cher, plus c’est facile et meilleur c’est, et plus il y a de chances qu’Open AI l’offre ! En attendant, n’hésitez pas à me contacter si vous avez des questions.