

























فابريس الذكاء الاصطناعي: التنفيذ التقني الحالي
في المنشور الأخير، فابريس للذكاء الاصطناعي: الرحلة التقنية شرحتُ الرحلة التي مررنا بها لبناء فابريس للذكاء الاصطناعي التي تقوم بدائرة كاملة. بدأت باستخدام Chat GPT 3 و 3.5. وبعد أن خاب أملي في النتائج، حاولت استخدام إطار عمل لانغشين لبناء نموذج الذكاء الاصطناعي الخاص بي فوقه، قبل أن أعود إلى Chat GPT بمجرد أن بدأوا في استخدام قواعد البيانات المتجهة وتحسين النتائج بشكل كبير باستخدام 4o.
إليك العملية الحالية لتدريب فابريس للذكاء الاصطناعي:
- تُخزَّن بيانات التدريب (منشورات المدونة، وعناوين URL على Youtube، وعناوين URL للبودكاست، وعناوين URL لملفات PDF، وعناوين URL للصور) في قاعدة بيانات WordPress الخاصة بنا.
- نستخرج البيانات وننظمها.
- نحن نقدم البيانات المهيكلة إلى Open AI للتدريب باستخدام واجهة برمجة تطبيقات المساعدين.
- ثم يقوم الذكاء الاصطناعي المفتوح بإنشاء قاعدة بيانات مخزن المتجهات وتخزينها.
فيما يلي مثال على جزء من البيانات المنظمة. لكل جزء من المحتوى ملف JSON خاص به. نحرص على عدم تجاوز حد الـ 32,000 توكن.
{
“معرف”: “1”,
“التاريخ”: ” “,
“الرابط”:”https://fabricegrinda.com/”,
“العنوان”: {
“المقدمة”: “ما هو “فابريس إيه آي”؟”
},
“الفئة”: “حول فابريس”,
“feature_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“وسائط_أخرى”: “”,
“نوع_المعرفة”: “مدونة”,
“تم تحديث المحتوى”: “فابريس الذكاء الاصطناعي هو تمثيل رقمي لأفكار فابريس استنادًا إلى منشورات مدونته وبعض المدونات الصوتية والمقابلات التي تم تفريغها باستخدام ChatGPT، ونظرًا لأن العديد من التدوينات تم تفريغها بشكل غير كامل وأن المدونة ليست سوى تمثيل محدود لفابريس الفرد، فإننا نعتذر عن عدم الدقة والمعلومات المفقودة. ومع ذلك، فهذه نقطة انطلاق جيدة للحصول على أفكار فابريس حول العديد من الموضوعات.”
}
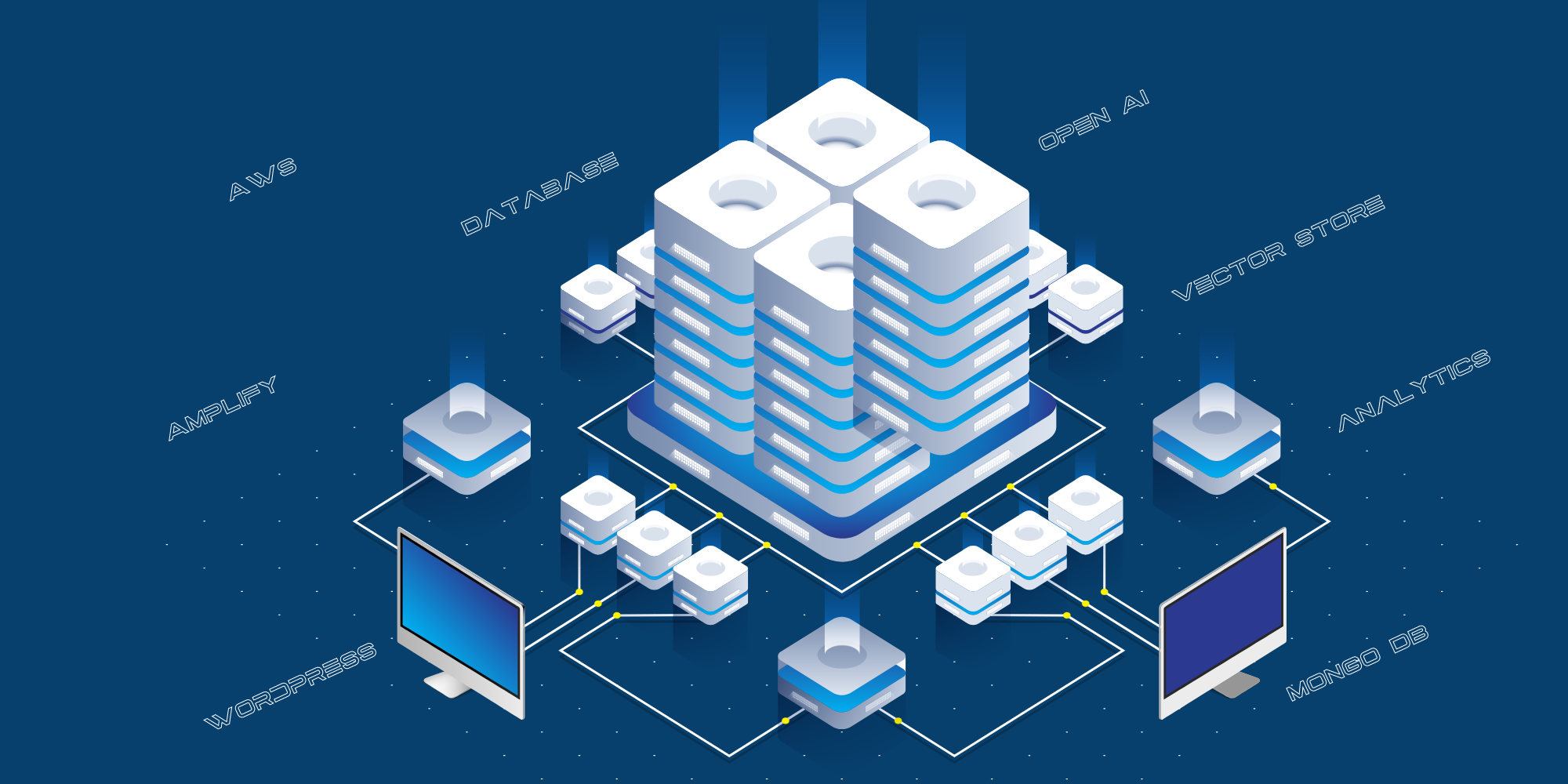
هذا هو التنفيذ الفني الحالي:
- تتم استضافة الموقع الإلكتروني الذي يواجه المستهلك على AWS Amplify.
- يتم التكامل بين الموقع العام والذكاء الاصطناعي المفتوح من خلال طبقة واجهة برمجة التطبيقات، والتي تتم استضافتها على AWS كخادم Python API.
- نحن نستخدم MongoDB كسجل لتخزين جميع الأسئلة التي طرحها الجمهور، والإجابات التي قدمتها Chat GPT، وعناوين URL الخاصة بالمصادر.
- نستخدم العديد من البرامج النصية لهيكلة البيانات من المدونة ويوتيوب وغيرها لتمريرها إلى Open AI للتدريب.
- نستخدم خاصية React-Speech Recognition لتحويل الاستفسارات الصوتية إلى نصوص.
- كما نستخدم أيضاً تحليلات جوجل أناليتكس لتتبع حركة المرور على الموقع الإلكتروني.
من المهم ملاحظة أننا نستخدم مساعدين اثنين:
- واحد للإجابة على الأسئلة.
- واحد للحصول على عناوين URL للبيانات الوصفية، عناوين URL للمدونة التي تحتوي على المحتوى الأصلي لعرض المصادر في أسفل الإجابات.
ما التالي؟
- تحسينات تحويل الكلام إلى نص
نموذج Whisper من Open AI لتحويل الكلام إلى نص أكثر دقة من React. كما أنه يدعم لغات متعددة من خارج الصندوق، وهو جيد في التعامل مع الكلام المختلط بين اللغات واللهجات واللهجات. ونتيجة لذلك، من المرجح أن أنتقل إليه في الأشهر القادمة. ومع ذلك، فإن إعداده أكثر تعقيداً، لذا قد يستغرق الأمر بعض الوقت. تحتاج إلى التعامل مع النموذج، وإدارة التبعيات (على سبيل المثال، بايثون والمكتبات)، والتأكد من أن لديك أجهزة كافية لأداء فعال. كما أن Whisper ليس مصممًا للاستخدام المباشر في المتصفحات. عند إنشاء تطبيق ويب، تحتاج إلى إنشاء خدمة خلفية للتعامل مع النسخ مما يضيف تعقيدًا.
- أفاتار فابريس للذكاء الاصطناعي
أريد إنشاء صورة رمزية للذكاء الاصطناعي فابريس تشبهني وتبدو مثلي ويمكنك إجراء محادثة معها. لقد قمت بتقييم D-iD لكنني وجدت أنه مكلف للغاية بالنسبة لأغراضي. مختبرات Eleven Labs صوتية فقط. Synthesia رائع ولكنه لا ينشئ حاليًا مقاطع فيديو في الوقت الفعلي. في النهاية قررت استخدام HeyGen نظراً للأسعار والوظائف الأكثر ملاءمة.
أظن أنه في مرحلة ما سيصدر Open AI حلاً خاصًا به في وقت ما، لذا سيكون هذا العمل قد ذهب سدى. أنا مرتاح لذلك وسأنتقل إلى حل الذكاء الاصطناعي المفتوح عندما يأتي الحل وإذا جاء. في هذه المرحلة، الهدف من هذا التمرين بأكمله هو معرفة ما هو ممكن مع الذكاء الاصطناعي ومقدار العمل الذي يتطلبه لمساعدتي على فهم الفضاء بشكل أفضل.
- لوحة التحكم المخصصة
في الوقت الحالي، أحتاج الآن إلى تشغيل استعلام MongoDB للحصول على مستخرج من أسئلة وإجابات اليوم. أقوم ببناء لوحة تحكم بسيطة حيث يمكنني الحصول على مستخرجات وإحصائيات بسيطة عن عدد الاستعلامات لكل لغة، وعدد طلبات تحويل الكلام إلى نص، إلخ.
- مصادر البيانات الإضافية
لقد قمنا للتو بتحميل محفظة FJ Labs إلى محفظة فابريس للذكاء الاصطناعي. يمكنك الآن السؤال عما إذا كانت الشركة جزءًا من المحفظة. يجيبك فابريس للذكاء الاصطناعي بوصف موجز للشركة ورابط لموقعها الإلكتروني.

نظرًا لعدد الأسئلة الشخصية التي كان يتلقاها الذكاء الاصطناعي فابريس والتي لم يكن لديه إجابات لها، فقد استغرقت وقتًا طويلاً لوضع علامة يدويًا على كل متحدث في فيديو عيد ميلادي الخمسين لإعطاء المحتوى الذي يحتاجه.

خاتمة
مع كل العمل الذي قمت به على مدار الاثني عشر شهرًا الماضية حول كل ما يتعلق بالذكاء الاصطناعي، يبدو أن هناك استنتاجًا عالميًا واضحًا: كلما انتظرت أكثر، كلما كان الأمر أرخص وأسهل وأفضل، وكلما زاد احتمال أن يقدمه الذكاء الاصطناعي المفتوح! في غضون ذلك، أعلمني إذا كان لديك أي أسئلة.