

























Fabrice AI: huidige technische implementatie
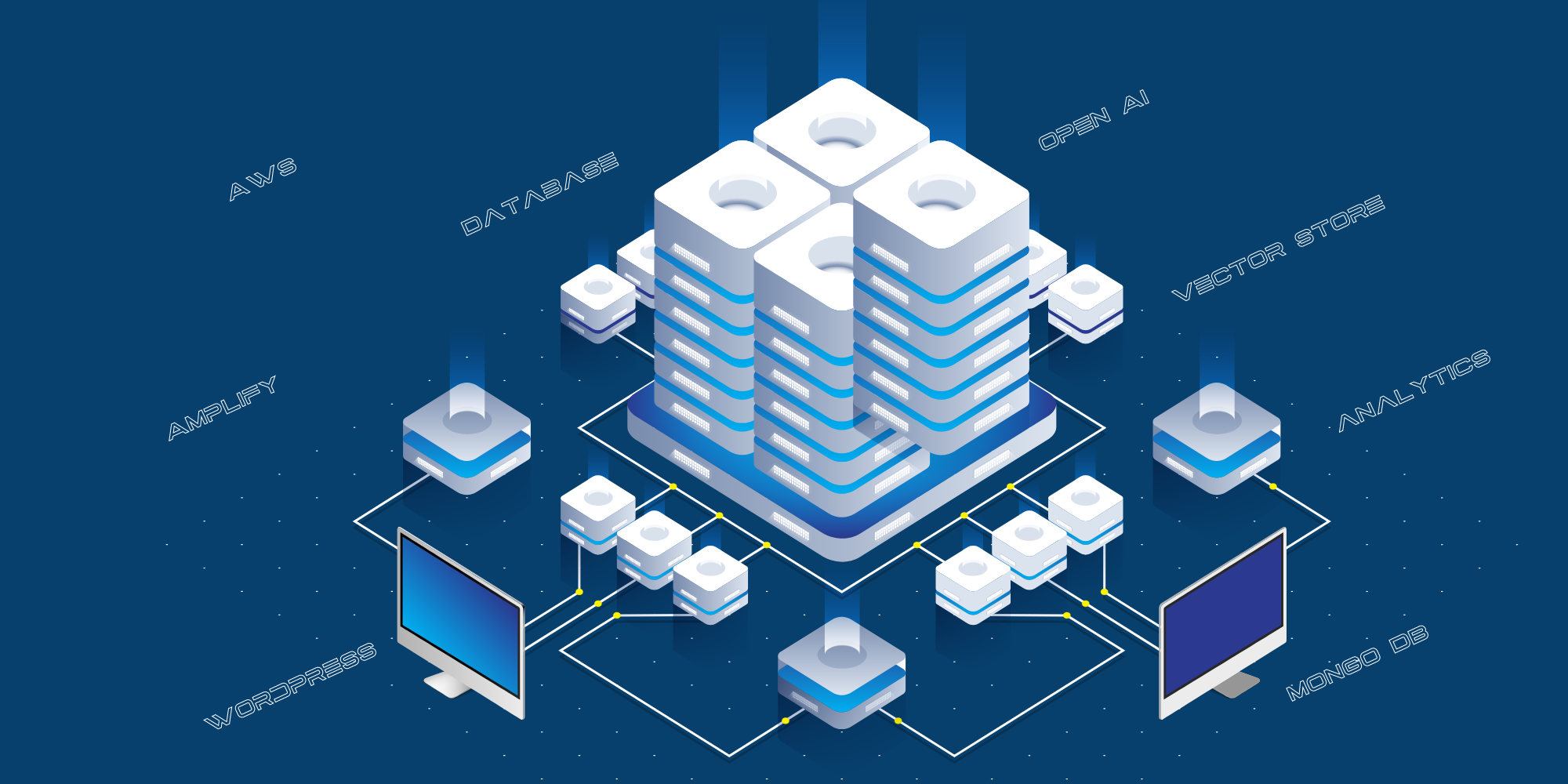
In de vorige post, Fabrice AI: The Technical Journey, heb ik uitgelegd hoe we Fabrice AI gebouwd hebben door een volledige cirkel te maken. Ik begon met het gebruik van Chat GPT 3 en 3.5. Teleurgesteld in de resultaten probeerde ik het Langchain Framework te gebruiken om mijn eigen AI-model erop te bouwen, voordat ik terugkeerde naar Chat GPT toen ze vectordatabases gingen gebruiken en de resultaten met 4o enorm verbeterden.
Dit is het huidige proces voor het trainen van Fabrice AI:
- De trainingsgegevens (blogberichten, Youtube-URL’s, podcast-URL’s, PDF-URL’s en URL’s van afbeeldingen) worden opgeslagen in onze WordPress-database.
- We extraheren de gegevens en structureren ze.
- We leveren de gestructureerde gegevens aan Open AI voor training met behulp van de Assistants API.
- Open AI maakt vervolgens een vectoropslagdatabase en slaat deze op.
Hier is een voorbeeld van gestructureerde gegevens. Elk stuk inhoud heeft zijn eigen JSON-bestand. We zorgen ervoor dat we de limiet van 32.000 tokens niet overschrijden.
{
“id”: “1”,
“datum”: ” “,
“link”:”https://fabricegrinda.com/”,
“title”: {
“weergegeven”: “Wat is Fabrice AI?”
},
“Categorie”: “Over Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“andere_media”: “”,
“kennis_type”: “blog”,
“contentUpdated”: “Fabrice AI is een digitale weergave van Fabrice’s gedachten op basis van zijn blog posts en geselecteerde getranscribeerde podcasts en interviews met behulp van ChatGPT.Gezien het feit dat veel van de transcripties onvolmaakt zijn getranscribeerd en dat de blog slechts een beperkte weergave is van Fabrice de persoon, verontschuldigen wij ons voor onnauwkeurigheden en ontbrekende informatie. Desalniettemin is dit een goed startpunt voor Fabrice’s gedachten over veel onderwerpen.”
}
Dit is de huidige technische implementatie:
- De website voor consumenten wordt gehost op AWS Amplify.
- De integratie tussen de openbare site en Open AI gebeurt via een API-laag, die wordt gehost op AWS als een Python API-server.
- We gebruiken MongoDB als logboek om alle vragen op te slaan die door het publiek zijn gesteld, de antwoorden die zijn gegeven door Chat GPT en de URL’s van de bronnen.
- We gebruiken verschillende scripts om de gegevens van de blog, YouTube, enz. te structureren en door te geven aan Open AI voor training.
- We gebruiken React-Speech Recognition om gesproken vragen om te zetten in tekst.
- We gebruiken ook Google Analytics om het websiteverkeer bij te houden.
Het is belangrijk om te weten dat we twee assistenten gebruiken:
- Eén voor het beantwoorden van vragen.
- Eén voor het verkrijgen van metadata URL’s, de blog URL’s die de originele inhoud hebben om de bronnen onderaan de antwoorden weer te geven.
Wat nu?
- Spraak-naar-tekst verbeteringen
Open AI’s Whisper-model voor spraak naar tekst is nauwkeuriger dan React. Het ondersteunt ook direct meerdere talen en is goed in het verwerken van spraak in verschillende talen, accenten en dialecten. Daarom zal ik er de komende maanden waarschijnlijk op overstappen. Dat gezegd hebbende, het is complexer om in te stellen, dus het kan even duren. Je moet omgaan met het model, afhankelijkheden beheren (bijv. Python, bibliotheken) en ervoor zorgen dat je voldoende hardware hebt voor efficiënte prestaties. Whisper is ook niet ontworpen voor direct gebruik in browsers. Als je een web app bouwt, moet je een backend service maken om de transcriptie af te handelen, wat complexiteit toevoegt.
- Fabrice AI Avatar
Ik wil een Fabrice AI Avatar maken die eruitziet en klinkt als ik en waarmee je een gesprek kunt voeren. Ik heb D-iD geëvalueerd maar vond het veel te duur voor mijn doeleinden. Eleven Labs is alleen geschikt voor spraak. Synthesia is geweldig, maar maakt momenteel geen video’s in realtime. Uiteindelijk besloot ik HeyGen te gebruiken vanwege de betere prijs en functionaliteit.
Ik vermoed dat Open AI op een gegeven moment zijn eigen oplossing zal uitbrengen, zodat dit werk voor niets is geweest. Ik voel me daar goed bij en zal overstappen naar de Open AI oplossing als die er komt. In dit stadium is het doel van deze hele oefening om te leren wat er mogelijk is met AI en hoeveel werk het vereist om me te helpen de ruimte beter te begrijpen.
- Aangepast dashboard
Op dit moment moet ik een MongoDB query uitvoeren om een extract van de vragen en antwoorden van de dag te krijgen. Ik ben een eenvoudig dashboard aan het bouwen waar ik extracties en eenvoudige statistieken kan opvragen over het aantal query’s per taal, het aantal spraak-naar-tekst verzoeken, enz.
- Aanvullende gegevensbronnen
We hebben zojuist de FJ Labs Portfolio geüpload naar Fabrice AI. Je kunt nu vragen of een bedrijf deel uitmaakt van het portfolio. Fabrice AI antwoordt met een korte beschrijving van het bedrijf en een link naar de website.

Gezien het aantal persoonlijke vragen dat Fabrice AI kreeg waar het geen antwoord op had, nam ik de tijd om elke spreker in mijn 50e Verjaardagsvideo handmatig te taggen om de inhoud te geven die het nodig had.

Conclusie
Met al het werk dat ik de afgelopen twaalf maanden heb gedaan aan alles wat met AI te maken heeft, lijkt er een duidelijke universele conclusie te zijn: hoe meer je wacht, hoe goedkoper, gemakkelijker en beter het wordt, en hoe waarschijnlijker dat Open AI het zal aanbieden! Laat het me in de tussentijd weten als je vragen hebt.