

























Fabrice AI: implementação técnica atual
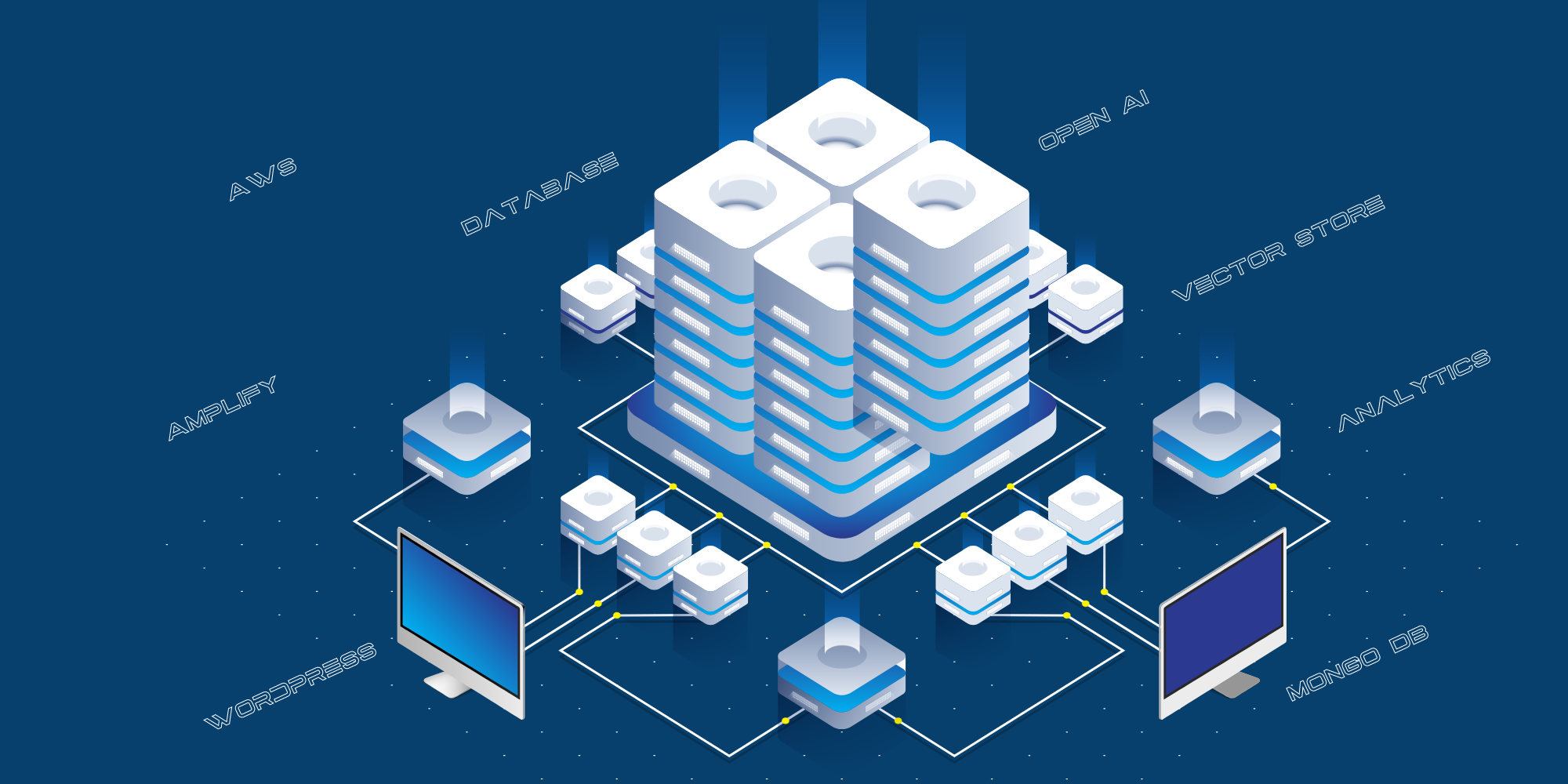
Na última publicação, Fabrice AI: A jornada técnica, expliquei a jornada que percorremos para criar a Fabrice AI, fazendo um círculo completo. Comecei usando o Chat GPT 3 e 3.5. Desapontado com os resultados, tentei usar a Langchain Framework para criar meu próprio modelo de IA em cima dela, antes de voltar ao Chat GPT quando eles começaram a usar bancos de dados vetoriais e a melhorar enormemente os resultados com o 4o.
Aqui está o processo atual de treinamento do Fabrice AI:
- Os dados de treinamento (publicações em blogs, URLs do YouTube, URLs de podcasts, URLs de PDFs e URLs de imagens) são armazenados em nosso banco de dados do WordPress.
- Extraímos os dados e os estruturamos.
- Fornecemos os dados estruturados à Open AI para treinamento usando a API Assistants.
- Em seguida, o Open AI cria um banco de dados de armazenamento de vetores e o armazena.
Aqui está um exemplo de um dado estruturado. Cada parte do conteúdo tem seu próprio arquivo JSON. Nós nos certificamos de não exceder o limite de 32.000 tokens.
{
“id”: “1”,
“data”: ” “,
“link”: “https://fabricegrinda.com/”,
“title”: {
“renderizado”: “O que é a IA de Fabrice?”
},
“Categoria”: “Sobre a Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“other_media”: “”,
“tipo de conhecimento”: “blog”,
“contentUpdated”: “Fabrice AI é uma representação digital dos pensamentos de Fabrice com base nas publicações de seu blog e em podcasts e entrevistas transcritos selecionados usando o ChatGPT. Como muitas das transcrições são imperfeitamente transcritas e o blog é apenas uma representação limitada de Fabrice, o indivíduo, pedimos desculpas por imprecisões e informações ausentes. No entanto, este é um bom ponto de partida para você conhecer as ideias de Fabrice sobre vários tópicos.”
}
Esta é a implementação técnica atual:
- O site voltado para o consumidor está hospedado no AWS Amplify.
- A integração entre o site público e o Open AI é feita por meio de uma camada de API, que é hospedada no AWS como um servidor de API Python.
- Usamos o MongoDB como um registro para armazenar todas as perguntas feitas pelo público, as respostas dadas pelo Chat GPT e os URLs das fontes.
- Usamos vários scripts para estruturar os dados do blog, do YouTube etc. para passar para o Open AI para treinamento.
- Usamos o React-Speech Recognition para converter as consultas de voz em texto.
- Também usamos o Google Analytics para monitorar o tráfego do site.
É importante observar que usamos dois assistentes:
- Um para responder a perguntas.
- Um para obter URLs de metadados, os URLs de blogs que têm o conteúdo original para exibir as fontes na parte inferior das respostas.
E agora?
- Melhorias na conversão de fala em texto
O modelo Whisper da Open AI para conversão de fala em texto é mais preciso do que o React. Ele também oferece suporte imediato a vários idiomas e é bom para lidar com fala em idiomas mistos, sotaques e dialetos. Como resultado, é provável que eu passe a usá-lo nos próximos meses. Dito isso, sua configuração é mais complexa, portanto, pode demorar um pouco. Você precisa lidar com o modelo, gerenciar as dependências (por exemplo, Python, bibliotecas) e garantir que tenha hardware suficiente para um desempenho eficiente. Além disso, o Whisper não foi projetado para uso direto em navegadores. Ao criar um aplicativo da Web, você precisa criar um serviço de backend para lidar com a transcrição, o que aumenta a complexidade.
- Avatar de Fabrice AI
Quero criar um avatar Fabrice AI que se pareça comigo e com o qual você possa conversar. Avaliei o D-iD, mas achei muito caro para meus objetivos. O Eleven Labs é somente para voz. O Synthesia é excelente, mas atualmente não cria vídeos em tempo real. No final, decidi usar o HeyGen devido ao preço e à funcionalidade mais adequados.
Suspeito que, em algum momento, o Open AI lançará sua própria solução, de modo que esse trabalho terá sido em vão. Estou confortável com isso e mudarei para a solução da Open AI quando e se ela for lançada. Nesse estágio, o objetivo de todo esse exercício é aprender o que é possível fazer com a IA e quanto trabalho é necessário para me ajudar a entender melhor o espaço.
- Painel de controle personalizado
No momento, preciso executar uma consulta ao MongoDB para obter um extrato das perguntas e respostas do dia. Estou criando um painel simples no qual posso obter extrações e estatísticas simples sobre o número de consultas por idioma, o número de solicitações de fala para texto etc.
- Fontes de dados adicionais
Acabamos de fazer o upload do portfólio da FJ Labs para a Fabrice AI. Agora você pode perguntar se uma empresa faz parte do portfólio. A Fabrice AI responde com uma breve descrição da empresa e um link para seu site.

Dado o número de perguntas pessoais que a Fabrice AI estava recebendo e para as quais não tinha respostas, reservei um tempo para marcar manualmente cada palestrante no meu vídeo de 50º aniversário para fornecer o conteúdo necessário.

Conclusão
Com todo o trabalho que fiz nos últimos doze meses sobre todos os assuntos relacionados à IA, parece haver uma conclusão universal clara: quanto mais você espera, mais barato, mais fácil e melhor fica, e mais provável que a Open AI ofereça isso! Enquanto isso, entre em contato comigo se você tiver alguma dúvida.