

























Fabrice AI: Implementação técnica atual
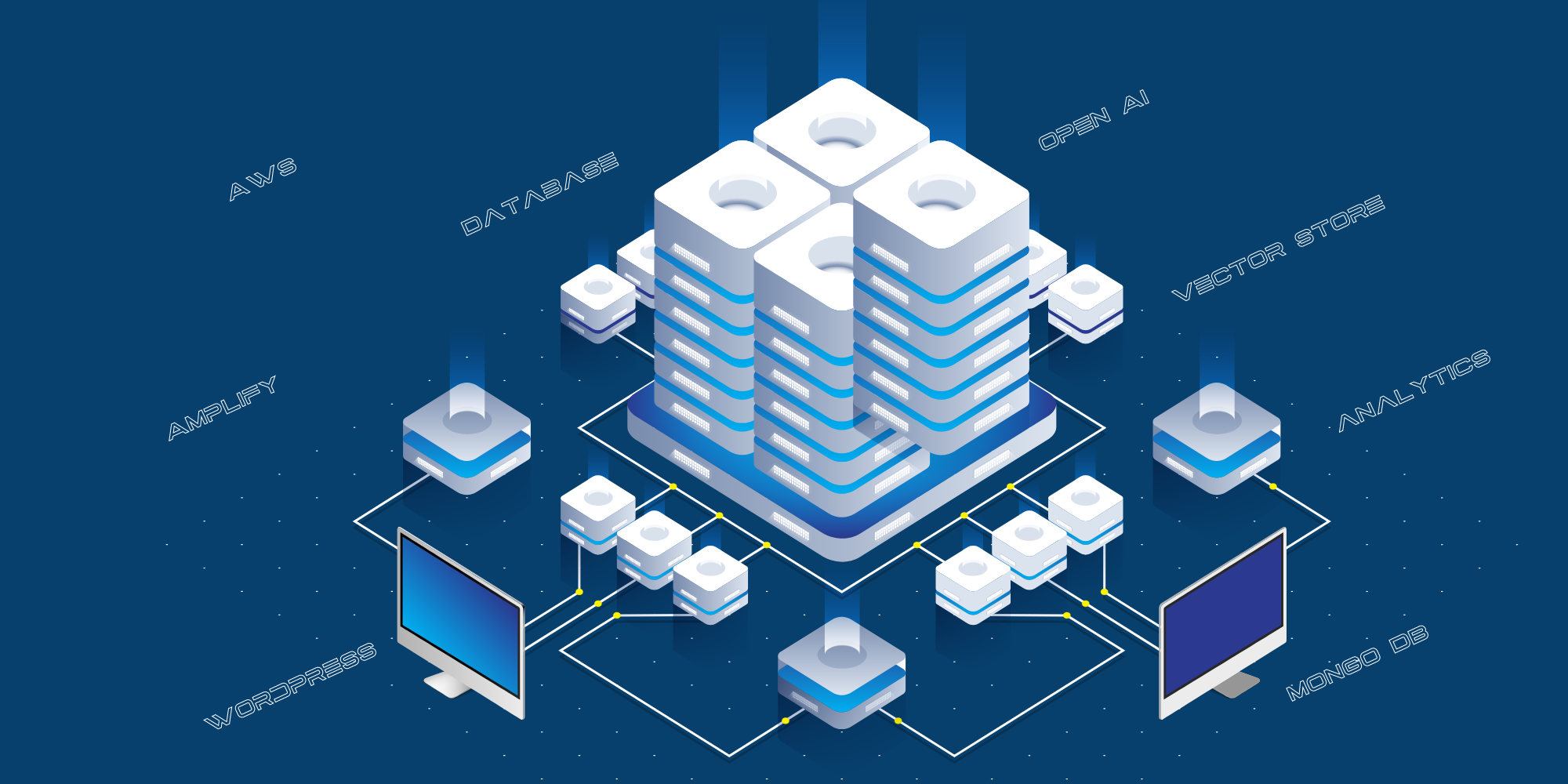
Na última publicação, Fabrice AI: O percurso técnico, expliquei o percurso que fizemos para construir a Fabrice AI, fazendo um círculo completo. Comecei por usar o Chat GPT 3 e 3.5. Desapontado com os resultados, tentei utilizar o Langchain Framework para construir o meu próprio modelo de IA em cima dele, antes de voltar ao Chat GPT quando começaram a utilizar bases de dados vectoriais e a melhorar imenso os resultados com o 4o.
Eis o processo atual de formação da IA do Fabrice:
- Os dados de treino (publicações de blogues, URLs do Youtube, URLs de podcasts, URLs de PDFs e URLs de imagens) são armazenados na nossa base de dados WordPress.
- Extraímos os dados e estruturamo-los.
- Fornecemos os dados estruturados à Open AI para treino utilizando a API Assistants.
- Em seguida, o Open AI cria uma base de dados de armazenamento de vectores e armazena-a.
Eis um exemplo de um dado estruturado. Cada parte do conteúdo tem o seu próprio ficheiro JSON. Certificamo-nos de que não excedemos o limite de 32.000 fichas.
{
“id”: “1”,
“data”: ” “,
“link”: “https://fabricegrinda.com/”,
“título”: {
“renderizado”: “O que é a IA do Fabrice?”
},
“Categoria”: “Sobre o Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“outros_meios”: “”,
“tipo de conhecimento”: “blogue”,
“contentUpdated”: “Dado que muitas das transcrições são imperfeitas e que o blogue é apenas uma representação limitada da pessoa Fabrice, pedimos desculpa pelas imprecisões e informações em falta. No entanto, este é um bom ponto de partida para conheceres as ideias de Fabrice sobre muitos temas.”
}
Esta é a implementação técnica atual:
- O sítio Web virado para o consumidor está alojado no AWS Amplify.
- A integração entre o sítio público e o Open AI é feita através de uma camada de API, que está alojada no AWS como um servidor de API Python.
- Usamos o MongoDB como registo para armazenar todas as perguntas feitas pelo público, as respostas dadas pelo Chat GPT e os URLs das fontes.
- Utilizamos vários scripts para estruturar os dados do blogue, do YouTube, etc., para os transmitir à Open AI para treino.
- Utilizamos o React-Speech Recognition para converter as perguntas de voz em texto.
- Também utilizamos o Google Analytics para controlar o tráfego do sítio Web.
É importante notar que utilizamos dois assistentes:
- Um para responderes a perguntas.
- Um para obter URLs de metadados, os URLs de blogues que têm o conteúdo original para apresentar as fontes no fundo das respostas.
O que vais fazer agora?
- Melhorias na conversão de voz em texto
O modelo Whisper da Open AI para conversão de voz em texto é mais preciso do que o React. Também suporta vários idiomas de imediato e é bom a lidar com discurso em vários idiomas, sotaques e dialectos. Por isso, é muito provável que o utilize nos próximos meses. Dito isto, a sua configuração é mais complexa, pelo que pode demorar algum tempo. Tens de tratar do modelo, gerir as dependências (por exemplo, Python, bibliotecas) e garantir que tens hardware suficiente para um desempenho eficiente. Além disso, o Whisper não foi concebido para utilização direta em browsers. Quando constrói uma aplicação Web, tem de criar um serviço de backend para tratar a transcrição, o que aumenta a complexidade.
- Avatar de Fabrice AI
Quero criar um avatar Fabrice AI que se pareça e soe como eu e com o qual possas ter uma conversa. Avaliei o D-iD, mas achei-o demasiado caro para os meus objectivos. O Eleven Labs é apenas para voz. O Synthesia é ótimo, mas atualmente não cria vídeos em tempo real. No final, decidi utilizar o HeyGen devido ao preço e à funcionalidade mais adequados.
Suspeito que, a dada altura, a Open AI lançará a sua própria solução, pelo que este trabalho terá sido em vão. Não me importo com isso e mudarei para a solução Open AI quando e se esta for lançada. Nesta fase, o objetivo de todo este exercício é aprender o que é possível fazer com a IA e quanto trabalho é necessário para me ajudar a compreender melhor o espaço.
- Painel de controlo personalizado
Neste momento, preciso de executar uma consulta MongoDB para obter um extrato das perguntas e respostas do dia. Estou a construir um painel de controlo simples onde posso obter extracções e estatísticas simples sobre o número de consultas por língua, o número de pedidos de voz para texto, etc.
- Fontes de dados adicionais
Acabámos de carregar o portfólio da FJ Labs na Fabrice AI. Agora, podes perguntar se uma empresa faz parte do portefólio. A Fabrice AI responde com uma breve descrição da empresa e uma ligação ao seu sítio Web.

Dado o número de perguntas pessoais que a Fabrice AI estava a receber e para as quais não tinha resposta, dediquei algum tempo a etiquetar manualmente cada orador no meu vídeo do 50º aniversário para lhe dar o conteúdo de que necessitava.

Conclusão
Com todo o trabalho que fiz nos últimos doze meses sobre todas as coisas relacionadas com a IA, parece haver uma conclusão universal clara: quanto mais esperares, mais barato, mais fácil e melhor se torna, e mais provável é que a IA aberta o ofereça! Entretanto, avisa-me se tiveres alguma dúvida.