

























Fabrice AI: Implementarea tehnică actuală
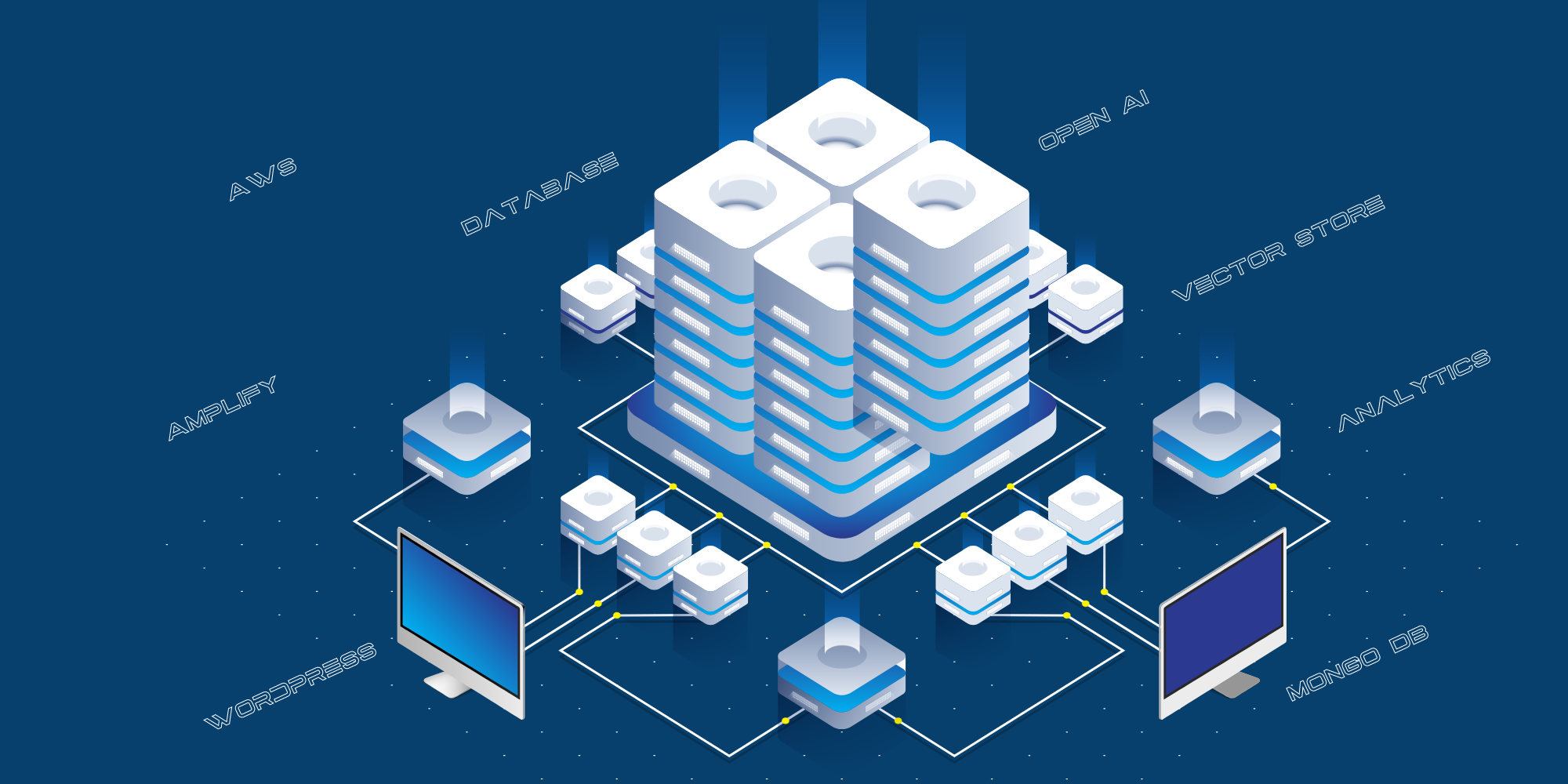
În ultima postare, Fabrice AI: Călătoria tehnică, am explicat călătoria prin care am trecut pentru a construi Fabrice AI făcând un cerc complet. Am început prin a utiliza Chat GPT 3 și 3.5. Dezamăgit de rezultate, am încercat să folosesc Langchain Framework pentru a-mi construi propriul model AI deasupra acestuia, înainte de a reveni la Chat GPT odată ce au început să folosească baze de date vectoriale și să îmbunătățească masiv rezultatele cu 4o.
Iată procesul actual de formare a lui Fabrice AI:
- Datele de formare (postări pe blog, URL-uri Youtube, URL-uri podcast-uri, URL-uri PDF și URL-uri de imagini) sunt stocate în baza noastră de date WordPress.
- Extragem datele și le structurăm.
- Noi furnizăm datele structurate către Open AI pentru instruire, utilizând API-ul Assistants.
- Open AI creează apoi o bază de date a magazinului de vectori și o stochează.
Iată un exemplu de bucată de date structurate. Fiecare bucată de conținut are propriul fișier JSON. Ne asigurăm să nu depășim limita de 32 000 de token-uri.
{
„id”: „1”,
„data”: ” „,
„link”:”https://fabricegrinda.com/”,
„title”: {
„redat”: „Ce este Fabrice AI?”
},
„Categorie”: „Despre Fabrice”,
„featured_media”: „https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
„other_media”: „”,
„knowledge_type”: „blog”,
„contentUpdated”: „Fabrice AI este o reprezentare digitală a gândurilor lui Fabrice pe baza postărilor de pe blogul său și a unor podcasturi și interviuri transcrise selecționate folosind ChatGPT.Având în vedere că multe dintre transcrieri sunt transcrise imperfect și că blogul este doar o reprezentare limitată a individului Fabrice, ne cerem scuze pentru inexactitățile și informațiile lipsă. Cu toate acestea, acesta este un bun punct de plecare pentru a obține gândurile lui Fabrice pe multe subiecte.”
}
Aceasta este implementarea tehnică actuală:
- Site-ul web destinat consumatorilor este găzduit pe AWS Amplify.
- Integrarea dintre site-ul public și Open AI se realizează prin intermediul unui strat API, care este găzduit pe AWS ca server API Python.
- Utilizăm MongoDB ca jurnal pentru a stoca toate întrebările adresate de public, răspunsurile date de Chat GPT și adresele URL ale surselor.
- Utilizăm diverse scripturi pentru a structura datele de pe blog, YouTube etc. pentru a le transmite către Open AI în vederea instruirii.
- Utilizăm React-Speech Recognition pentru a converti solicitările vocale în text.
- De asemenea, utilizăm Google Analytics pentru a urmări traficul pe site.
Este important să rețineți că folosim doi asistenți:
- Unul pentru a răspunde la întrebări.
- Unul pentru obținerea URL-urilor metadatelor, URL-urile blogurilor care au conținutul original pentru a afișa sursele în partea de jos a răspunsurilor.
Ce urmează?
- Îmbunătățiri de la vorbire la text
Modelul Whisper al Open AI pentru conversia vocii în text este mai precis decât React. De asemenea, suportă mai multe limbi din fabrică și este bun la gestionarea vorbirii în limbi mixte, accente și dialecte. Ca urmare, cel mai probabil voi trece la el în lunile următoare. Acestea fiind spuse, configurarea este mai complexă, așa că s-ar putea să dureze ceva timp. Trebuie să vă ocupați de model, să gestionați dependențele (de exemplu, Python, biblioteci) și să vă asigurați că aveți suficient hardware pentru o performanță eficientă. De asemenea, Whisper nu este conceput pentru utilizarea directă în browsere. Atunci când construiți o aplicație web, trebuie să creați un serviciu backend pentru a gestiona transcrierea, ceea ce adaugă complexitate.
- Fabrice AI Avatar
Vreau să creez un avatar Fabrice AI care arată și sună ca mine și cu care puteți purta o conversație. Am evaluat D-iD, dar l-am găsit mult prea scump pentru scopurile mele. Eleven Labs este doar pentru voce. Synthesia este grozav, dar în prezent nu creează videoclipuri în timp real. În cele din urmă, am decis să folosesc HeyGen, având în vedere prețul și funcționalitatea mai adecvate.
Bănuiesc că, la un moment dat, Open AI își va lansa propria soluție, astfel încât această muncă va fi fost în zadar. Nu mă deranjează acest lucru și voi trece la soluția Open AI când și dacă aceasta va apărea. În acest stadiu, scopul acestui exercițiu este de a afla ce este posibil cu ajutorul inteligenței artificiale și cât de multă muncă este necesară pentru a mă ajuta să înțeleg mai bine spațiul.
- Tablou de bord personalizat
În acest moment, trebuie să execut o interogare MongoDB pentru a obține un extras al întrebărilor și răspunsurilor zilei. Construiesc un tablou de bord simplu în care pot obține extrageri și statistici simple privind numărul de interogări pe limbă, numărul de cereri speech-to-text etc.
- Surse suplimentare de date
Tocmai am încărcat portofoliul FJ Labs la Fabrice AI. Acum puteți întreba dacă o companie face parte din portofoliu. Fabrice AI răspunde cu o scurtă descriere a companiei și un link către site-ul acesteia.

Având în vedere numărul mare de întrebări personale pe care Fabrice AI le primea și la care nu avea răspuns, mi-am făcut timp să etichetez manual fiecare vorbitor din videoclipul meu cu aniversarea a 50 de ani pentru a-i oferi conținutul de care avea nevoie.

Concluzie
Cu toată munca pe care am desfășurat-o în ultimele douăsprezece luni cu privire la toate aspectele legate de inteligența artificială, se pare că există o concluzie universală clară: cu cât aștepți mai mult, cu atât devine mai ieftin, mai ușor și mai bun, și cu atât este mai probabil ca Open AI să ofere acest lucru! Între timp, dați-mi de știre dacă aveți întrebări.