

























Фабріс АІ: поточна технічна реалізація
У попередній статті, Fabrice AI: Технічна подорож, я описав шлях, який ми пройшли, щоб побудувати Fabrice AI, зробивши повне коло. Я почав з використання Chat GPT 3 і 3.5. Розчарований результатами, я спробував використати Langchain Framework, щоб побудувати власну модель ШІ на його основі, а потім повернувся до Chat GPT, коли вони почали використовувати векторні бази даних і значно покращили результати за допомогою 4o.
Ось поточний процес навчання Фабріса ШІ:
- Навчальні дані (дописи в блогах, URL-адреси Youtube, URL-адреси подкастів, URL-адреси PDF та URL-адреси зображень) зберігаються в нашій базі даних WordPress.
- Ми витягуємо дані та структуруємо їх.
- Ми надаємо структуровані дані Open AI для навчання за допомогою Assistants API.
- Потім Open AI створює базу даних векторів і зберігає її.
Ось приклад фрагмента структурованих даних. Кожна частина контенту має власний JSON-файл. Ми стежимо за тим, щоб не перевищити ліміт у 32 000 токенів.
{
“id”: “1”,
“дата”: ” “,
“link”: “https://fabricegrinda.com/”,
“title”: {
“рендеринг”: “Що таке Fabrice AI?”
},
“Категорія”: “Про Фабріса”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“інші_медіа”: “”,
“knowledge_type”: “blog”,
“contentUpdated”: “Fabrice AI – це цифрове представлення думок Фабріса, засноване на його записах в блозі і вибраних транскрибованих подкастах та інтерв’ю за допомогою ChatGPT. Враховуючи, що багато транскрипцій є недосконалими і що блог є лише обмеженим представленням особистості Фабріса, ми просимо вибачення за неточності і відсутню інформацію. Тим не менш, це хороша відправна точка, щоб отримати уявлення про думки Фабріса на багато тем”.
}
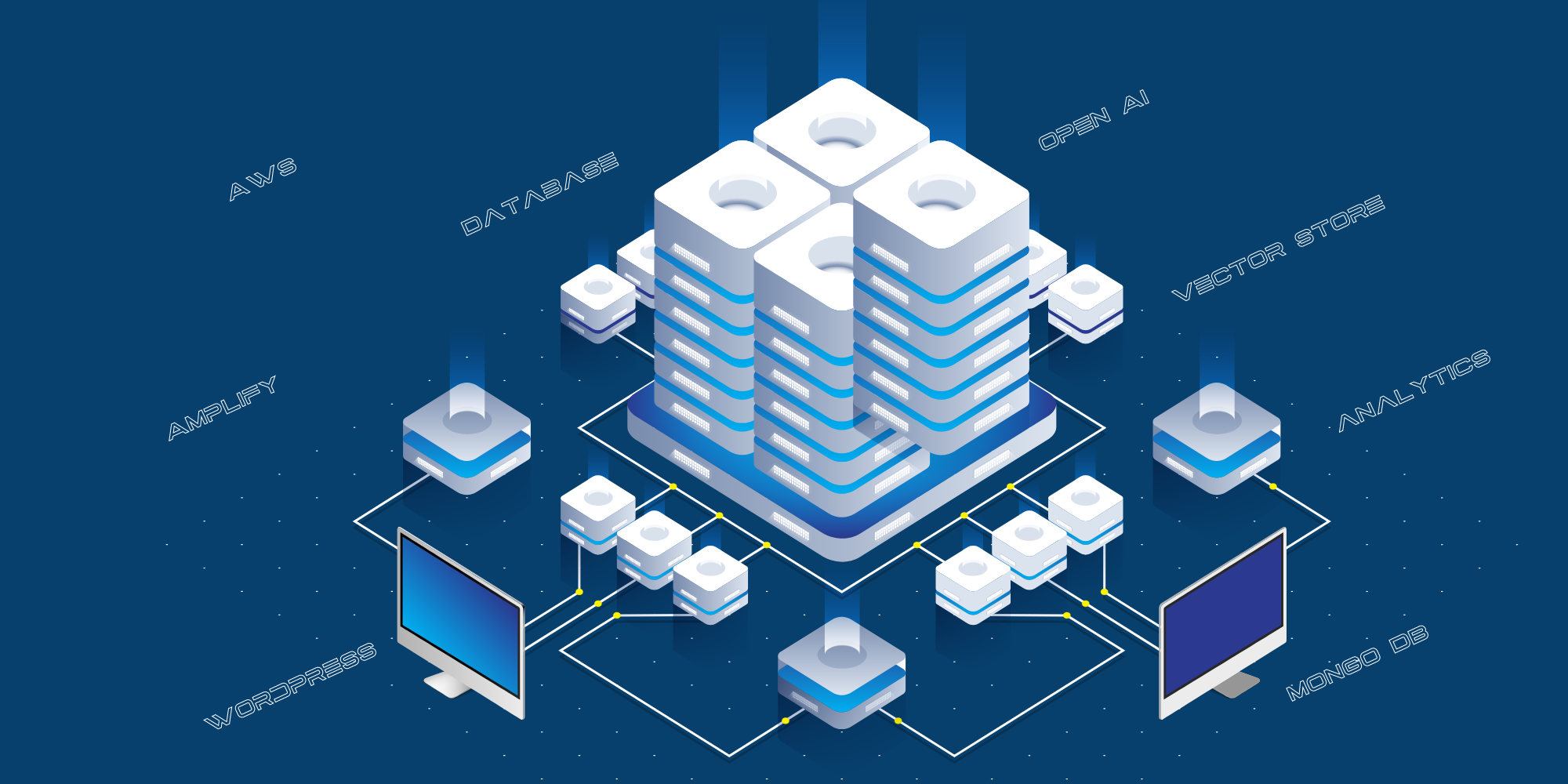
Це поточна технічна реалізація:
- Веб-сайт, орієнтований на споживача, розміщений на AWS Amplify.
- Інтеграція між загальнодоступним сайтом та Відкритим ШІ здійснюється через рівень API, який розміщено на AWS як сервер API Python.
- Ми використовуємо MongoDB як журнал для зберігання всіх запитань, заданих користувачами, відповідей, наданих чатом GPT, та URL-адрес джерел.
- Ми використовуємо різні скрипти, щоб структурувати дані з блогу, YouTube тощо для передачі Open AI для навчання.
- Ми використовуємо React-Speech Recognition для перетворення голосових запитів на текст.
- Ми також використовуємо Google Analytics для відстеження відвідуваності сайту.
Важливо зазначити, що ми використовуємо двох асистентів:
- Один для відповідей на запитання.
- Один для отримання URL-адрес метаданих, URL-адрес блогів, які мають оригінальний вміст для відображення джерел внизу відповідей.
Що далі?
- Покращення перетворення мови в текст
Модель Whisper від Open AI для перетворення мови в текст точніша, ніж у React. Він також підтримує кілька мов з коробки і добре справляється з мішаною мовою, акцентами та діалектами. Тому я, швидше за все, перейду на нього в найближчі місяці. Проте його складніше налаштовувати, тому це може зайняти деякий час. Вам потрібно розібратися з моделлю, керувати залежностями (наприклад, Python, бібліотеками) і переконатися, що у вас достатньо апаратних засобів для ефективної роботи. Крім того, Whisper не призначений для прямого використання в браузерах. При створенні веб-додатку вам потрібно створити внутрішній сервіс для обробки транскрипції, що додає складності.
- Фабріс А.І. Аватар
Я хочу створити аватар зі штучним інтелектом Фабріса, який виглядатиме і звучатиме, як я, і з яким можна буде розмовляти. Я оцінив D-iD, але він виявився занадто дорогим для моїх цілей. Eleven Labs працює лише з голосом. Synthesia – чудовий, але наразі не створює відео в режимі реального часу. Зрештою, я вирішив використовувати HeyGen через більш прийнятну ціну та функціональність.
Підозрюю, що в якийсь момент Open AI випустить власне рішення, і вся ця робота буде марною. Мене це влаштовує, і я перейду на рішення Open AI, коли і якщо воно з’явиться. На даному етапі сенс всієї цієї вправи полягає в тому, щоб дізнатися, що можливо за допомогою штучного інтелекту і скільки роботи він вимагає, щоб допомогти мені краще розуміти простір.
- Кастомізована інформаційна панель
Зараз мені потрібно виконати запит до MongoDB, щоб отримати витяг із запитань та відповідей за день. Я створюю просту інформаційну панель, де я можу отримувати витяги та просту статистику про кількість запитів на кожну мову, кількість запитів на перетворення мови в текст і т.д.
- Додаткові джерела даних
Ми щойно завантажили портфоліо FJ Labs до Fabrice AI. Тепер ви можете запитати, чи є компанія в портфоліо. Fabrice AI відповість вам коротким описом компанії та посиланням на її веб-сайт.

Враховуючи кількість особистих запитань, які отримував Fabrice AI і на які він не мав відповідей, я знайшов час, щоб вручну позначити кожного спікера у моєму відео на 50-й день народження, щоб надати йому необхідний контент.

Висновок
З усієї роботи, яку я проробив за останні дванадцять місяців над усіма питаннями, пов’язаними зі штучним інтелектом, можна зробити чіткий універсальний висновок: чим більше ви чекаєте, тим дешевше, простіше і краще це стає, і тим більша ймовірність того, що Open AI запропонує це! А поки що дайте мені знати, якщо у вас виникнуть запитання.